#7 Two dreaded words, part 2
Last week (here) I suggested that the term standard deviation inspires the most dread in introductory statistics students. I argued that this is very unfortunate because standard deviation (SD) is simply a measure of variability, the most fundamental concept in statistics. I proposed some questions that might help students to develop a better understanding of what SD measures. But none of my questions made use of real data, so l will fix that deficiency here in part two.
But first I want to mention a textbook exercise with real data that I encountered near the beginning of my teaching career in the early 1990s. The question gave seat belt usage percentages for each of the fifty states. The data were real, and the context was interesting. The textbook question asked: Calculate the standard deviation of these 50 seat belt usage percentages. That’s it. Students were not asked to interpret the value of the SD. They were not asked to graph the data and describe the distribution. They were just asked to calculate the value of an SD for some unspecified reason. I joked to myself that a student would deserve full credit for answering this textbook exercise not with the requested calculation but with a one-word response: Why?
This reminds me that I used to collect data from my students by asking how many keys they were carrying. My students would then analyze the data and describe the distribution. A friend eventually worked up the nerve to ask me that devastating one-word question: Why? I had to admit that I had no motivating question in mind behind collecting these data, so I realized that it was a pointless exercise and abandoned it.
What’s my point behind these digressions? First, as I tried to demonstrate in the previous post, I think you can ask good questions without real data. Second, my point now is that you can ask bad questions with real data. In mathematicians’ words, I believe that using real data is neither necessary nor sufficient for asking good* questions.
* I have not forgotten that I promised in my first post (link) to consider the issue of what makes a question good. I still promise to come back to that eventually.
Don’t get me wrong: I’m a big proponent of using real data. Let’s get to some good questions using real data that address the dreaded topic of standard deviation (SD). As always, questions that I pose to students appear in italics.
People love to talk about the weather as one of the most variable, changeable aspects of the world around us. In many locations around the world one can hear local residents advise: “If you don’t like the weather right now, just wait an hour.” But how variable is the weather in different locations? I went to weather.com to look up the high temperatures for the 28 days of February 2019 for four locations: San Luis Obispo, California; Juneau, Alaska; Princeville, Hawaii; and Sedona, Arizona. Before we look at the data, make a prediction for the ordering of these four locations in terms of the SD of their February high temperatures.
I don’t really care whether students know much about the weather in these places, although I encourage them to discuss this with each other. Then I show them this graph of the data:
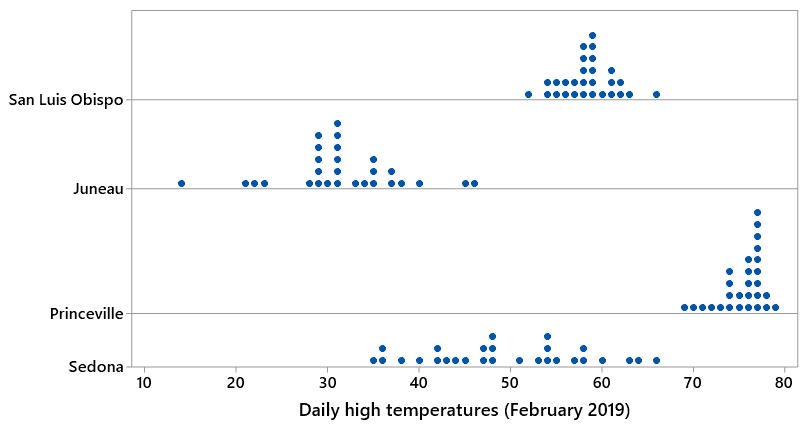
Based on what this graph reveals, put these locations in order from smallest to largest SD of their daily February temperatures.
Now I do care that students can read the graphs properly and understand the relative amounts of variability in these distributions. San Luis Obispo (SLO) and Princeville clearly have less variability in temperatures than Juneau and Sedona, despite having higher temperatures on average. Princeville has slightly less variability than SLO. If you do not like high temperatures between 70 and 80 degrees, then do not spend February in Princeville! On the other hand, if you want to experience a variety of temperatures, consider spending February in Sedona, where high temperatures ranged from 35 to 66 degrees, giving Sedona the most variability among these locations. Here are the SDs, in order from smallest to largest:

What if we looked at daily high temperatures in July instead of February? Would we see a very different story or a similar one? More specifically: Which of these four locations would you predict to have a larger SD in July than in February? Which would you predict to have a smaller SD? What is your predicted ordering of the four locations by SD of daily July temperatures?
Let’s look at a graph of the data:
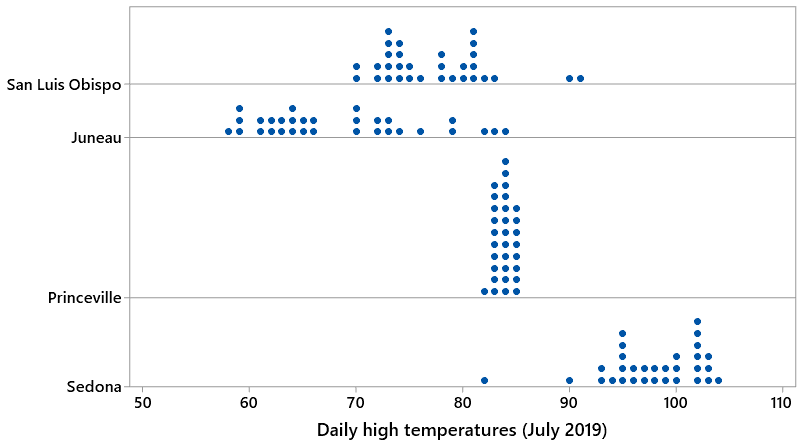
With the benefit of seeing this graph, re-answer the previous questions.
Now you’d better avoid Princeville if you cannot abide high temperatures between 82 and 85 degrees! In fact, the variability in Princeville’s high temperatures has gone from small in February to miniscule in July, with an SD of less than 1 degree. Sedona’s variability has also decreased considerably, even as its temperatures have soared into the 90s and low 100s. On the flip side, temperatures in San Luis Obispo and Juneau are more variable (substantially for SLO, slightly for Juneau) in July than they were in February.
Here are the new SDs, which reveal that Sedona’s temperature variability has dropped from the highest to second lowest:

One final observation and question for students before we leave these data behind: Sedona’s smallest high temperature in July 2019 was 82 degrees, which occurred on the very last day of the month. What would happen to Sedona’s SD of July temperatures – decrease or increase or remain pretty much the same – if we were to remove the 82 value?
Removing that outlier would decrease the variability considerably and so would decrease the SD. It turns out that the decrease in SD would be from 4.69 degrees to 3.73 degrees, less than half of the SD value from February in Sedona.
Students can be encouraged to extend this analysis outside of class. They could use weather.com to collect their own data to analyze, perhaps from other locations across the country or other parts of the world. They could also analyze temperatures for different months, or for the same month across different years. They could also analyze weather data other than daily high temperatures.
Now let’s move to sports, where a popular word is parity. This means that teams in a league are roughly evenly matched, which allows fans of many teams to entertain somewhat realistic hopes of winning a championship. Do some sports and some leagues/conferences have more parity than others?
I investigated this question by recording the win proportion* for each team in the 2018 Major League Baseball season. Then I grouped the teams according to whether they are in the National League (NL) or American League (AL). The purpose is to see whether one league or the other has substantially more parity among its teams’ win proportions.
* For example, the Boston Red Sox achieved the best win-loss record of 108-54, for a win proportion of 108/162 ≈ 0.667. On the other extreme, the Baltimore Orioles had the worst win-loss record of 47-115, for a win proportion of 47/162 ≈ 0.290.
The first question for students is: Would a smaller or larger SD of win proportions indicate greater parity in a sports league? Most students realize that greater parity means less variability, which requires a smaller SD.
The next question is for baseball fans only: Make an educated guess for which league – NL or AL – had a smaller SD of its teams’ win proportions in the 2018 season.
Let’s look at a graph of the distributions of win proportions for the two leagues:
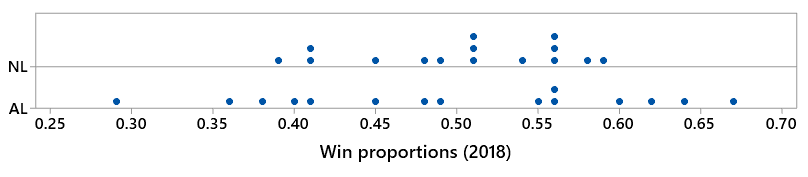
Now we arrive at the key question for all students, not just baseball fans: Based on the graph, which league had a smaller SD of win proportions?
Most students correctly realize that the National League (NL) has a considerably smaller SD of win proportions, and therefore more parity, than the American League (AL). Teams were generally much closer in their win proportions, and therefore more middle-of-the-pack in quality, in the NL. In fact, 14 of 15 teams in the NL won between 40% and 60% of their games. (Only the Miami Marlins missed out, and just barely, with their 0.391 win proportion.) In contrast, only 8 of 15 AL teams won between 40% and 60% of their games. The AL was more of a feast-or-famine league, as it was home to the four teams with the best win proportions (Boston Red Sox, Houston Astros, New York Yankees, Oakland Athletics) and the three teams with the worst win proportions (Baltimore Orioles, Kansas City Royals, Chicago White Sox).
The SDs of the win proportions turn out to be .065 in the NL, .113 in the AL. Then I ask students: Calculate the percentage difference in these SD values. This is not trivial for most introductory students, and I plan to devote a future post to this under-appreciated topic. The calculation of this percentage difference is: (.113 – .065) / .065 ≈ .738 × 100% = 73.8%. Interpret this value in this context. The SD of win proportions in the AL was 73.8% larger than the SD of win proportions in the NL. This seems like a very large discrepancy in parity between the two leagues.
Let’s look at two other sports: football and basketball. I gathered the same kind of data on win proportions for the 2018 National Football League (NFL) season and the 2018-19 National Basketball Association (NBA) season. Let’s start with some questions for sports fans: How do you expect the SDs of win proportions to compare across the three sports: baseball, football, basketball? Within football and basketball, do you expect to see much of a difference in the SDs of win proportions between the two conferences? In which of the three sports do you expect to see the largest discrepancy in SDs of win proportions between the two leagues/conferences?
Then I ask all students to answer these questions based on the following graph of the data (where the top two dotplots are for the two baseball leagues, the next two are for the two football conferences, and the bottom two are for the two basketball conferences):
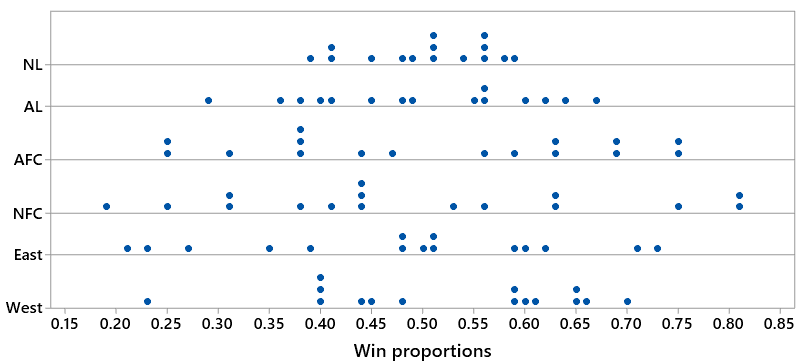
What do we see here? First, baseball has the least variability in win proportions, and football has the most variability. This makes sense in terms of the number of games in each sport’s season: Baseball has the longest season (162 games), followed by basketball (82 games) and finally football (16 games). Second, football and basketball do not have the large discrepancy in SDs between their conferences that baseball has between its leagues. The AFC appears to have a slightly smaller SD than the NFC in football, and the Western conference appears to have a slightly smaller SD than the Eastern conference in basketball. The following SD values bear this out:

As with the weather data, students could be encouraged to extend this analysis to other sports data that they could collect. They could analyze other sports, perhaps at college or high school levels, or other years, or use a different variable than win proportions.
Almost all of these questions, for both weather and sports, have boiled down to asking: Look at the graph of the distributions, and arrange the groups in order according to magnitude of their SDs. So, if that’s all the questions asked, why is the length of this post surpassing 2000 words? I like to think that this illustrates one of the great things about using real data: The context can pull you in, inspiring you* to explore more aspects and analyze additional data in the hope of gaining more insights.
* And your students!
P.S. The datasets that I analyzed in this post can be downloaded from the links below.


Just discovered this blog and bookmarked it. I’m enjoying reading about all of your great questions and how you use them in class.
LikeLike
I really like this activity. Students hear “mean, median, mode” and zone out, thinking they already know all there is to know about measures of center. And, now they pretty much everyone calculates the SD using technology, students focus on HOW to just calculate the SD (with calculator or software) rather than knowing what this is measuring.
This website gives the data in an easy-to-grab way for daily temperatures by state/city: https://www.usclimatedata.com/
LikeLike