#8 End of the alphabet
As you might imagine, considering the first letter of my first name, I am rather partial to the first letter of the alphabet. Students also seem to be quite fond of this letter, perhaps because it represents the grade that they are working toward. Nevertheless, despite the attractions of the letter A, I often draw my students’ attention to the very end of the alphabet, because I think z-scores represent an important and underappreciated concept in introductory statistics.
Some believe that the sole purpose of a z-score is to provide an intermediate step in a normal probability calculation. Moreover, this step has been rendered obsolete by technology. But the idea of measuring distance in terms of number of standard deviations is very useful and relevant in many situations. This is what z-scores do, and this enables us to compare proverbial apples and oranges. Four examples follow. As always, my questions to students appear in italics.
1. I introduce students to this concept in a context that they are quite familiar with: standardized exams such as the SAT and ACT. Suppose that Bob achieves a score of 1250 on the SAT, and his sister Kathy scores 29 on the ACT. Who did better, relative to their peers? What more information do you need?
Students realize that it’s meaningless to compare scores of 1250 and 29, because the two exams are scored on completely different scales. I provide some more information:
- SAT scores have a mound-shaped distribution with a mean of about 1050 and a standard deviation (SD) of about 200.
- ACT scores have a mound-shaped distribution with a mean of about 21 and an SD of about 5.5.
Now what can you say about who did better relative to their peers – Bob or Kathy?
At this point some students come up with the key insight: compare the two siblings in terms of how many standard deviations above the mean their test scores are. It’s fairly easy to see that Bob’s score is exactly 1 SD above the mean on the SAT. We can also see that Kathy’s score is more than 1 SD above the mean on the ACT, because 21 + 5.5 = 26.5 is less than Kathy’s score of 29. With a little more thought and effort, we can calculate that Kathy’s score is (29 – 21) / 5.5 ≈ 1.45 SDs above the mean. Therefore, it’s reasonable to conclude that Kathy did better than Bob relative to their peers.
Next I introduce the term z-score (also known as a standard score or standardized score) for what we have calculated here: the number of standard deviations above or below the mean a value is. I’m tempted not to give a formula for calculating a z-score, but then I succumb to orthodoxy and present: z = (x – mean) / SD.
Now let’s consider two more siblings, Peter and Kellen. Peter scores 650 on the SAT, and Kellen scores 13 on the ACT. Who did better, relative to their peers? Explain.
Having figured out a reasonable approach with Bob and Kathy, students are on much firmer ground now. Peter’s score is exactly 2 SDs below the mean on the SAT, and Kellen’s score is between 1 and 2 SDs below the mean on the ACT. In fact, Kellen’s z-score can be calculated to be (13 – 21) / 5.5 ≈ -1.45, so his ACT score is 1.45 SDs below average. Because Kellen’s score is closer to average than Peter’s, and because both scored below average, Kellen did somewhat better relative to his peers than Peter.
We could produce graphs to compare these distributions and siblings:
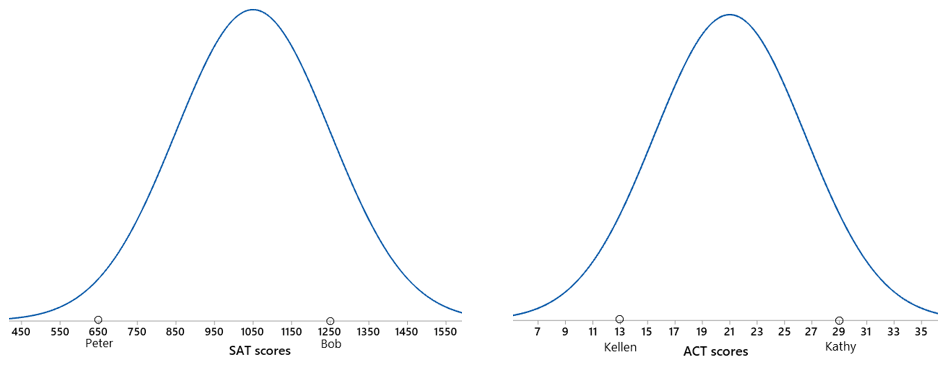
The graphs help to make clear that Kathy’s score is farther out than Bob’s in the right tail of their distributions and that Peter’s score is farther out in the left tail than Kellen’s. You could take the natural next step here and calculate percentiles from normal distributions for each sibling, but I usually stop short of that step to keep the focus on z-scores.
Next I’d like to show you one of my favorite* questions from an AP Statistics exam. This question, taken from the 2011 exam, is about evaluating players based on speed and strength. Even though the question mentions no particular sport or position, I’ll always think of this as the “linebacker” question.
* I discussed my all-time favorite question in post #2 (link).
Here’s the first part of the question:

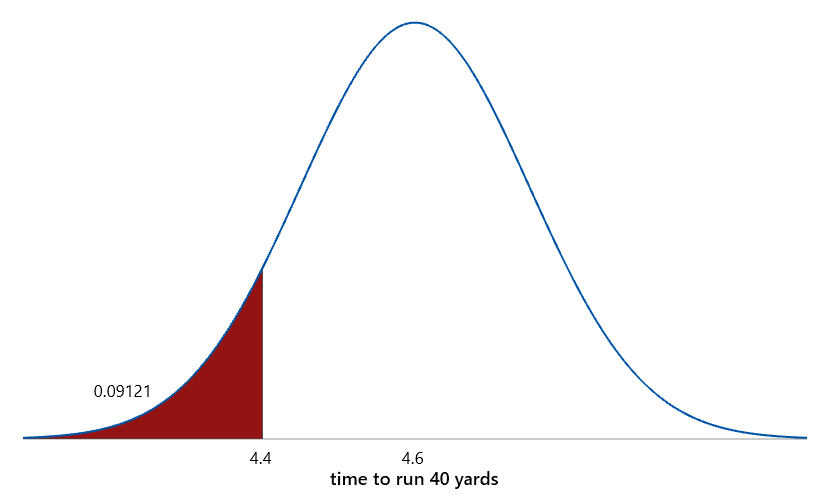
This is a very challenging question to start the exam. Rather than ask for a routine calculation or interpretation, this question requires students to think things through. Students need to realize that the minimum time is too close to the mean for the normal distribution to provide a reasonable model. What does “too close” mean here? That’s the whole point: Let’s measure that closeness in number of standard deviations. In other words, let’s look to the end of the alphabet and calculate a z-score for the minimum time: z = (4.40 – 4.60) / 0.15 ≈ -1.33. What does this z-score tell us? The minimum time is only 1.33 standard deviations below the mean. Why does this indicate that a normal distribution would be unreasonable? As shown in the graph below, with a normal distribution, about 9% of the data would fall more than 1.33 SDs below the mean, so we would expect the minimum time to be farther below the mean than that.
On to the second part of the question:
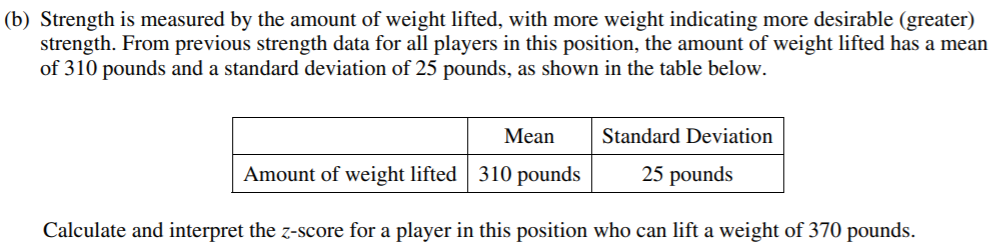
This part is very straight-forward, allowing students to do something routine that they might have practiced repeatedly, and there’s certainly nothing wrong with that. This z-score can be calculated to be: z = (370 – 310) / 25 = 2.40. Notice that the interpretation is as important as the calculation: This z-score tells us that a player who can lift 370 pounds is lifting 2.4 SDs more than average. Saying that this weight is 2.4 SDs away from the average would leave out important information about direction; students who gave this response did not receive full credit.
Here’s the final part of the question:
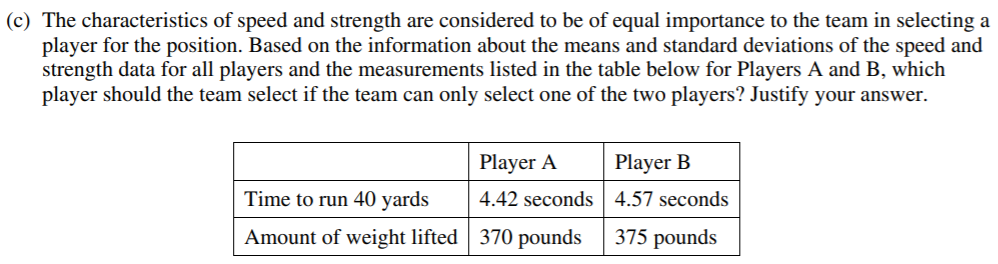
Most students saw that Player A was faster but less strong than Player B. Students then needed to realize that z-scores would be an effective way to compare the players on the two criteria. Some students had the intuition that a 5-pound difference in weightlifting amount (B’s advantage over A) is less impressive than a 0.15-second difference in running time (A’s advantage over B), but they needed to justify this conclusion by looking at SDs. A savvy student might have recognized that part (b) pointed them in a helpful direction by asking explicitly for a z-score calculation and interpretation.
The z-scores for speed turn out to be -1.2 for Player A, -0.2 for Player B. (Smaller values for time are better, indicating faster speed.) The z-scores for strength turn out to be 2.4 for Player A, 2.6 for Player B. Comparing these allows us to say that Player B is only slightly stronger than Player A, but Player A is considerably faster than Player B. Because the question advised us to consider both criteria as equally valuable, Player A is the better choice.
3. I also want students to have a sense for what constitutes a large z-score. For example, z-scores larger than 3 in absolute value do not come along very often. This is especially relevant when conducting significance tests for population proportions. It’s easy for students (and instructors) to get so caught up in blindly following the steps of a significance test that they lose sight of interpreting and drawing a conclusion from a z-score. A favorite example of mine concerns Hans Rosling, who dedicated his life to increasing public awareness of global health issues and achieved some internet fame for his entertaining and informative TED talks (link). Rosling and his colleagues liked to ask groups of people: Has the percentage of the world’s population who live in extreme poverty doubled, halved, or remained about the same over the past twenty years? The correct answer is that this percentage has halved, but only 5% of a sample of 1005 U.S. adults in 2017 got this right. Rosling liked to say that chimpanzees would do better than people: With only three options, we would expect 33.33% of chimpanzees to answer correctly.
I ask students: How far apart are these proportions: .05 for a sample of U.S. adults versus .3333 for blind guessing? What conclusion about Rosling’s hypothesis can you draw? Explain how your conclusion follows from that calculation.
This is exactly what a z-score can tell us. First we need to know the standard deviation of the sample proportion, assuming that people are guessing among the three options. We could use a simulation analysis to estimate this standard deviation, or we could use the familiar formula that results in:
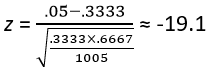
At this point many students would not pause for a moment before proceeding to use software or a graphing calculator or a normal probability table to determine the p-value, but I strongly encourage pausing to think about that enormous z-score! The observed value of the sample proportion (5% who answered correctly) is 19.1 standard deviations below the value one-third that would be expected from random guessers such as chimpanzees!!* We don’t need statistical software or an applet or a normal probability table to tell us that this is a HUGE discrepancy. This means that there’s (essentially) no way in the world that as few as 5% of a random sample would have answered correctly in a population where everyone blindly guesses. We have overwhelming evidence in support of Rosling’s claim that humans (at least U.S. adults) do worse than guessing (like chimpanzees would) on this question.
* With a z-score of -19.1, I joke with students that writing a correct interpretation with no exclamation points is only worth half-credit.
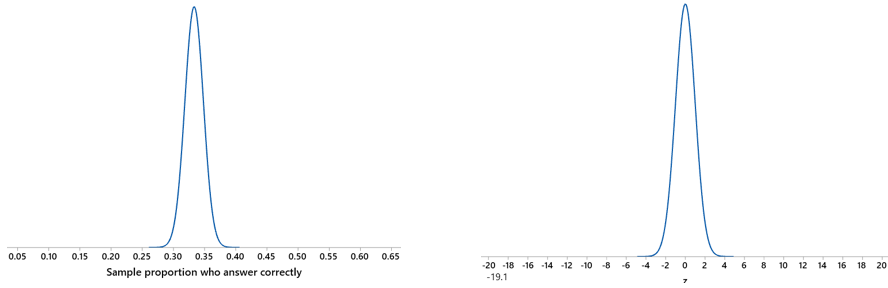
Some normal curve graphs might help to put this in perspective. The graph on the left below shows the distribution of sample proportions with a sample size of 1005, assuming that the population proportion equals one-third. We can see that a sample proportion of .05 is extremely far out in the tail. Equivalently, the graph on the right shows a z-score of -19.1 with a standard normal distribution:
4. Suppose that Arturo and Bella take an exam for which the mean score is 70 and standard deviation of scores is 8. Arturo’s score on the exam is 75, and Bella’s score is 1.5 standard deviations above Arturo’s score. What is Bella’s score on the exam? Show your work.
Notice that this question is not asking for a z-score calculation. I have recently started to ask this question on exams, because I began to worry that students were simply memorizing the mechanics of calculating a z-score and interpreting the result by rote. I figured that they might be able to do that without really understanding the concept of “number of standard deviations” away. By asking for a value that is 1.5 standard deviations away from a value that is not the mean, I think this question assesses student understanding. I’m happy to say that most of my students were able to answer this question correctly: Bella’s score is 75 + 1.5×8 = 75 + 12 = 87.
Where does this leave us? Whether your first name is Abel or Allison, Zachary or Zoya, or (most likely) something in between, I hope we can agree that when it comes to teaching introductory statistics, the last letter of the alphabet is not least important.
Trackbacks & Pingbacks
- #14 How confident are you? part 1 | Ask Good Questions
- #21 Twenty final exam questions | Ask Good Questions
- #22 Four more exam questions | Ask Good Questions
- #26 Group quizzes, part 2 | Ask Good Questions
- #33 Reveal human progress, part 1 | Ask Good Questions
- #36 Nearly normal | Ask Good Questions
- #52 Top thirteen topics | Ask Good Questions
- #71 An SBI quiz | Ask Good Questions
- #73 No notes needed | Ask Good Questions


My granddaughter’s name is Aadhya – how many standard deviations is that from the mean (alphabetical) name?
LikeLike
I love your good questions. Unfortunately I teach in a state where we start the school year at the beginning of August so all of your ideas are three weeks too late for me. But I am filing them away for next year!
LikeLike
Hmmm, those names ring a bell.
LikeLike
I’m embarrassed to say that I do t understand how the denominator in part 3. Is calculated for the SD of the sample. Since it is a sample why is n used and not n-1. I also don’t see what the numerator values of the SD calculation come from. Could you help me understand this better? Thanks!
LikeLike
Thanks for your question. Example 3 there compares a sample proportion to a hypothesized value for a population proportion. The standard deviation of a sample proportion is: SD(p-hat) = sqrt[p(1-p)/n]. Assuming that the population proportion equals one-third, and noting that the sample size is 1005, SD(p-hat) becomes sqrt(1/3 * 2/3 / 1005).
LikeLiked by 1 person
Thank you for the quick reply and explanation! I am enjoying your blog and appreciate your insights!!
LikeLike