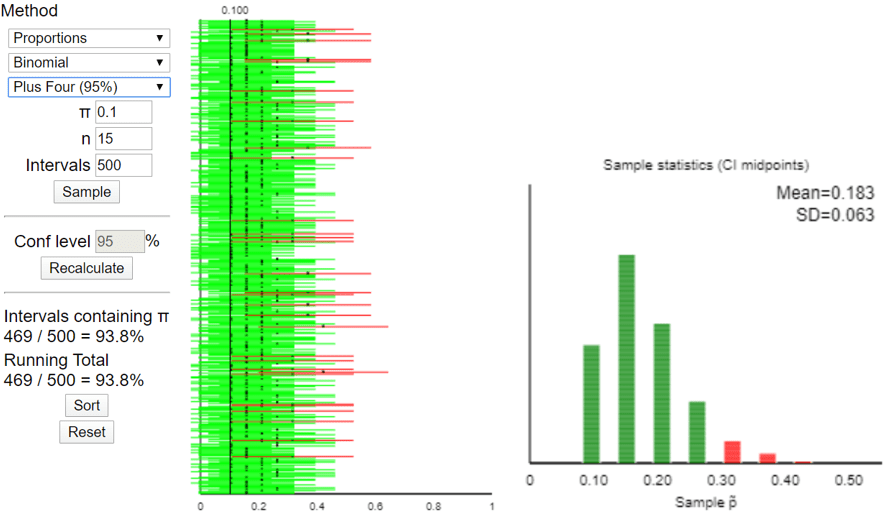
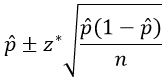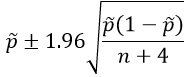#47 My favorite problem, part 1
I described my favorite question in post #2 (here) and my favorite theorem in post #10 (here). Now I present my favorite problem and show how I present this to students. I have presented this to statistics and mathematics majors in a probability course, as a colloquium for math and stat majors at other institutions, and for high school students in a problem-solving course or math club. I admit that the problem is not especially important or even realistic, but it has a lot of virtues: 1) easy to understand the problem and follow along to a Key Insight, 2) produces a Remarkable Result, 3) demonstrates problem-solving under uncertainty, and 4) allows me to convey my enthusiasm for probability and decision-making. Mostly, though, this problem is: 5) a lot of fun!
I take about 50 minutes to present this problem to students. For the purpose of this blog, I will split this into a three-part series. To enable you to keep track of where we’ve been and where we’re going, here’s an outline:

I believe that students at all levels, including middle school, can follow all of part 1, and the Key Insight that emerges in section 3 is not to be missed. The derivation in section 4 gets fairly math-y, so some students might want to skim or skip that section. But then sections 6 and 7 are widely accessible, providing students with practice applying the optimal strategy and giving a hint at the Remarkable Result to come. Sections 8 and 9 require some calculus, both derivatives and integrals. Students who have not studied calculus could skip ahead to the confirmation of the Remarkable Result at the end of section 9.
As always, questions that I pose to students appear in italics.
1. A personal story
Before we jump in, I’ll ask for your indulgence as I begin with an autobiographical digression*.
* Am I using this word correctly here – is it possible to digress even before the story begins? Hmm, I should look into that. But I digress …
In the fall of 1984, I was a first-year graduate student in the Statistics Department at Carnegie Mellon University. My professors and classmates were so brilliant, and the coursework was so demanding, that I felt under-prepared and overwhelmed. I was questioning whether I had made the right decision in going to graduate school. I even felt intimidated in the one course that was meant to be a cakewalk: Stat 705, Perspectives on Statistics. This course consisted of faculty talking informally to new graduate students about interesting problems or projects that they were working on, but I was dismayed that even these talks went over my head. I was especially dreading going to class on the day that the most renowned faculty member in the department, Morrie DeGroot, was scheduled to speak. He presented a problem that he called “choosing the best,” which is more commonly known as the “secretary problem.” I thought it was a fascinating problem with an ingenious solution. Even better, I understood it! Morrie’s talk went a long way in convincing me that I was in the right place after all.
When I began looking for undergraduate teaching positions several years later, I used Morrie’s “choosing the best” problem for my teaching demonstration during job interviews. It didn’t go very well. One reason is that I did not think carefully enough about how to adapt the problem for presenting to undergraduates. Another reason is that, being a novice teacher, I had not yet come to realize the importance of structuring my presentation around … (wait for it) …. asking good questions!
A few years later, I revised my “choosing the best” presentation to make it accessible and (I hope) engaging for students at both undergraduate and high school levels. Since the, I have enjoyed giving this talk to many groups of students. This is my first attempt to put this presentation in writing.
2. The problem statement, and making predictions
Here’s the background of the problem: Your task is to hire a new employee for your company. Your supervisor imposes the following restrictions on the hiring process:
- You know how many candidates have applied for the position.
- The candidates arrive to be interviewed in random order.
- You interview candidates one at a time.
- You can rank the candidates that you have interviewed from best to worst, but you have no prior knowledge about the quality of the candidates. In other words, after you’ve interviewed one person, you have no idea whether she is a good candidate or not. After you’ve interviewed two people, you know who is better and who is worse (ties are not allowed), but you do not know how they compare to the candidates yet to be interviewed. And so on …
- Once you have interviewed a candidate, you must decide immediately whether to hire that person. If you decide to hire, the process ends, and all of the other candidates are sent home. If you opt not to hire, the process continues, but you can no longer consider any candidates that you have previously interviewed. (You might assume that some other company has snatched up the candidates that you decided to pass on.)
- Your supervisor will be satisfied only if you hire the best candidate. Hiring the second best candidate is no better than hiring the very worst.
The first three of these conditions seem very reasonable. The fourth one is a bit limiting, but the last two are incredibly restrictive! You have to make a decision immediately after seeing each candidate? You can never go back and reconsider a candidate that you’ve seen earlier? You’ve failed if you don’t hire the very best candidate? How can you have any chance of succeeding at this seemingly impossible task? That’s what we’re about to find out.
To prompt students to think about how daunting this task is, I start by asking: For each of the numbers of candidates given in the table, make a guess for the optimal probability that you will succeed at hiring the best candidate.

Many students look at me blankly when I first ask for their guesses. I explain that the first entry means that only two people apply for the job. Make a guess for the probability that you successfully select the best candidate, according to the rules described above. Then make a guess for this probability when four people apply. Then increase the applicant pool to 12 people, and then 24 people. Think about whether you expect this probability to increase, decrease, or stay the same as the number of candidates increases. Then what if 50, or 500, or 5000 people apply – how likely are you to select the very best applicant, subject to the harsh rules we’ve discussed? Finally, the last entry is an estimate of the total number of people in the world (obtained here on May 24, 2020). What’s your guess for the probability of selecting the very best candidate if every single person on the planet applies for the job?
I hope that students guess around 0.5 for the first probability and then make smaller probability guesses as the number of candidates increases. I expect pretty small guesses with 24 candidates, extremely small guesses with 500 candidates, and incredibly small guesses with about 7.78 billion candidates*.
* With my students, I try to play up the idea of how small these probabilities must be, but some of them are perceptive enough to realize that this would not be my favorite problem unless it turns out that we can do much, much better than most people expect.
We’ll start by using brute-force enumeration to analyze this problem for small numbers of candidates.
Suppose that only one candidate applies: What will you do? What is your probability of choosing the best candidate?
This is a great situation, right? You have no choice but to hire this person, and they are certainly the best candidate among those who applied, so your probability of successfully choosing the best is 1!*
* I joke with students that the exclamation point here really does mean one-factorial. I have to admit that in a typical class of 35 or so students, the number who appreciate this joke is usually no larger than 1!
Now suppose that two candidates apply. In how many different orderings can the two candidates arrive? There are two possible orderings: A) The better candidate comes first and the worse one second, or B) the worse candidate comes first and the better one second. Let me use the notation 12 for ordering A, 21 for the ordering B.
What are your options for your decision-making process here? Well, you can hire the first person in line, or you can hire the second person in line. Remember that rule #4 means that after you have interviewed the first candidate, you have no idea as to whether the candidate was a strong or weak one. So, you really do not gain any helpful information upon interviewing the first candidate.
What are the probabilities of choosing the best candidate with these options? There’s nothing clever or complicated here. You succeed if you hire the first person with ordering A, and you succeed if you hire the second person with ordering B. These two orderings are equally likely, so your probability of choosing the best is 0.5 for either option.
I understand that we’re not off to an exciting start. But stay tuned, because we’re about to discover the Key Insight that will ratchet up the excitement level.
Now suppose that three candidates apply. How many different orderings of the three candidates are possible? Here are the six possible orderings:
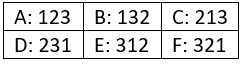
What should your hiring strategy be? One thought is to hire the first person in line. Then what’s your probability of choosing the best? Orderings A and B lead to success, and the others do not, so your probability of choosing the best is 2/6, also known as 1/3. What if you decide to hire the second person in line? Same thing: orderings C and E produce success, so the probability of choosing the best is again 2/6. Okay, then how about deciding to hire the last person in line? Again the same: 2/6 probability of success (D and F produce success).
Well, that’s pretty boring. At this point you’re probably wondering why in the world this is my favorite problem. But I’ll let you in on a little secret: We can do better. We can adopt a more clever strategy that achieves a higher success probability than one-third. Perhaps you’ve already had the Key Insight.
Let’s think through this hiring process one step at a time. Imagine yourself sitting at your desk, waiting to interview the three candidates who have lined up in the hallway. You interview the first candidate. Should you hire that person? Definitely not, because you’re stuck with that 1/3 probability of success if you do that. So, you should thank the first candidate but say that you will continue looking. Move on to interview the second candidate.
Should you hire that second candidate? This is the pivotal moment. Think about this. The correct answer is … Wait, I really want you to think about this before you read on. You’ve interviewed the second candidate. What should you decide? Are you ready with your answer? Okay, then … Wait, have you really thought this through before you read on?
The optimal answer to whether you should hire the second candidate consists of two words : It depends. On what does it depend? On whether the second candidate is better or worse than the first one. If the second person is better than the first one, should you hire that person? Sure, go ahead. But if the second person is worse than the first one, should you hire that person? Absolutely not! In this case, you know for sure that you’re not choosing the best if you hire the second person knowing that the first one was better. The only sensible decision is to take your chances with the third candidate.
You caught that, right? That was the Key Insight I’ve been promising. You learn something by interviewing the first candidate, because that enables you to discern whether the second candidate is better or worse than the first. You can use this knowledge to increase your probability of choosing the best.
To make sure that we’re all clear about this, let me summarize the strategy: Interview the first candidate but do not hire her. Then if the second candidate is better than the first, hire the second candidate. But if the second candidate is worse than the first, hire the third candidate.
Determine the probability of successfully choosing the best with this strategy. For students who need a hint: For each of the six possible orderings, determine whether or not this strategy succeeds at choosing the best.
First notice that orderings A (123) and B (132) do not lead to success, because the best candidate is first in line. But ordering C (213) is a winner: The second candidate is better than the first, so you hire her, and she is in fact the best. Ordering D (231) takes advantage of the key insight: The second candidate is worse than the first, so you keep going and hire the third candidate, who is indeed the best. Ordering E (312) is also a winner. But with ordering F (321), you hire the second person, because she is better than the first person, not knowing that the best candidate is still waiting in the wings. The orderings for which you succeed in choosing the best are shown with + in bold green here:
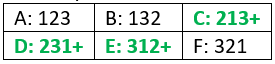
The probability of successfully choosing the best is therefore 3/6 = 0.5. Increasing the number of candidates from 2 to 3 does not reduce the probability of choosing the best, as long as you use the strategy based on the Key Insight.
Now let’s consider the case with 4 candidates. How many different orderings are possible? The answer is 4! = 24, as shown here:
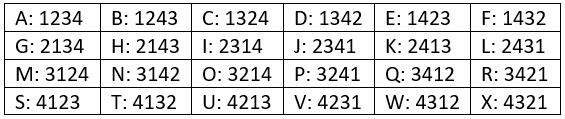
Again we’ll make use of the Key Insight. You should certainly not hire the first candidate in line. Instead use the knowledge gained from interviewing that candidate to assess whether subsequent candidates are better or worse. Whenever you find a candidate who is the best that you have encountered, hire her. We still need to decide between these two hiring strategies:
- Let the first candidate go by. Then hire the next candidate you see who is the best so far.
- Let the first two candidates go by. Then hire the next candidate you see who is the best so far.
How can we decide between these two hiring strategies? For students who need a hint, I offer: Make use of the list of 24 orderings. We’re again going to use a brute force analysis here, nothing clever. For each of the two strategies, we’ll go through all 24 orderings and figure out which lead to successfully choosing the best. Then we’ll count how many orderings produce winners for the first strategy and how many do so for the second strategy.
Go ahead and do this. At this point I encourage students to work in groups and give them 5-10 minutes to conduct this analysis. I ask them to mark the ordering with * if it produces a success with the first strategy and with a # if it leads to success with the second strategy. After a minute or two, to make sure that we’re all on the same page, I ask: What do you notice about the first row of orderings? A student will point out that the best candidate always arrives first in that row, which means that you never succeed in choosing the best with either of these strategies. We can effectively start with the second row.
Many students ask about ordering L (2431), wondering whether either strategy calls for hiring the third candidate because she is better than the second one. I respond by asking whether the third candidate is the best that you have seen so far. The answer is no, because the first candidate was better. Both strategies say to keep going until you find a candidate who is better than all that you have seen before that point.
When most of the student groups have finished, I go through the orderings one at a time and ask them to tell me whether or not it results in success for the “let 1 go by” strategy. As we’ve already discussed, the first row, in which the best candidate arrives first, does not produce any successes. But the second row tells a very different story. All six orderings in the second row produce success for the “let 1 go by” strategy. Because the second-best candidate arrives first in the second row, this strategy guarantees that you’ll keep looking until you find the very best candidate. The third row is a mixed bag. Orderings M and N are winners because the best candidate is second in line. Orderings O and P are instructive, because we are fooled into hiring the second-best candidate and leave the best waiting in the wings. Ordering Q produces success but R does not. In the fourth row, the first two orderings are winners but the rest are not. Here’s the table, with successes marked by $ in bold green:

How about the “let 2 go by” strategy? Again the first row produces no successes. The first two columns are also unlucky, because the best candidate was second in line and therefore passed over. Among the orderings that are left, all produce successes except R and X, where we are fooled into hiring the second-best candidate. Orderings O, P, U, V, and W are worth noting, because they lead to success for the “let 2 go by” strategy but not for “let 1 go by.” Here’s the table for the “let 2 go by” strategy, with successes marked by # in bold green:

So, which strategy does better? It’s a close call, but we see 11 successes with “let 1 go by” (marked with $) and 10 successes with ”let 2 go by” (indicated by #). The probability of choosing the best is therefore 11/24 ≈ 0.4583 by using the optimal (let 1 go by) strategy with 4 candidates.
How does this probability compare to the optimal strategy with 3 candidates? The probability has decreased a bit, from 0.5 to 0.4583. This is not surprising; we knew that the task gets more challenging as the number of candidates increases. What is surprising is that the decrease in this probability has been so small as we moved from 2 to 3 to 4 candidates. How does this probability compare to the naïve strategy of hiring the first person in line with 4 candidates? We’re doing a lot better than that, because 45.83% is a much higher success rate than 25%.
These examples with very small numbers of candidates suggest the general form of the optimal* strategy:
- Let a certain number of candidates go by.
- Then hire the first candidate you see who is the best among all you have seen thus far.
* I admit to mathematically inclined students that I have not formally proven that this strategy is optimal. For a proof, see Morrie DeGroot’s classic book Optimal Statistical Decisions.
Ready for one more? Now suppose that there are 5 candidates. What’s your guess for the optimal strategy – let 1 go by, or let 2 go by, or let 3 go by? In other words, the question is whether we want to garner information from just one candidate before we seriously consider hiring, or if it’s better to learn from two candidates before we get serious, or perhaps it’s best to take a look at three candidates. I don’t care what students guess, but I do want them to reflect on the Key Insight underlying this question before they proceed. How many possible orderings are there? There are now 5! =120 possible orderings. Do you want to spend your time analyzing these 120 orderings by brute force, as we did with 24 orderings in the case of 4 candidates? I am not disappointed when students answer no, because I hope this daunting task motivates them to want to analyze the general case mathematically. Just for fun, let me show the 120 orderings:
We could go through all 120 orderings one at a time. For each one, we could figure out whether it’s a winner or a loser with the “let 1 go by” strategy, and then repeat for “let 2 go by,” and then again for “let 3 go by.” I do not ask my students to perform such a tedious task, and I’m not asking you to do that either. How about if I just tell you how this turns out? The “let 1 go by” strategy produces a successful outcome for 50 of the orderings, compared to 52 orderings for “let 2 go by” and 42 orderings for “let 3 go by.”
Describe the optimal strategy with 5 candidates. Let the first 2 candidates go by. Then hire the first candidate you see who is the best you’ve seen to that point. What is the probability of success with that strategy? This probability is 52/120 ≈ 0.4333. Interpret this probability. If you were to use the optimal strategy with 5 candidates over and over and over again, you would successfully choose the best candidate in about 43.33% of those situations. Has this probability decreased from the case with 4 candidates? Yes, but only slightly, from 45.83% to 43.33%. Is this probability larger than a naïve approach of hiring the first candidate? Yes, a 43.33% chance is much greater than a 1/5 = 20% chance.
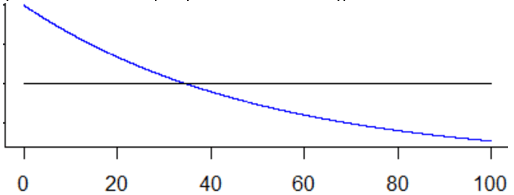
We’ve accomplished a good bit, thanks to the Key Insight that we discovered in the case with three candidates. Here is a graph of the probability of choosing the best with the optimal strategy, as a function of the number of candidates:
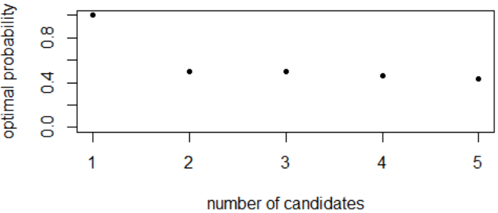
Sure enough, this probability is getting smaller as the number of candidates increases. But it’s getting smaller at a much slower pace than most people expect. What do you think will happen as we increase the number of candidates? I’ll ask you to revise your guesses from the beginning of this activity, based on what we have learned thus far. Please make new guesses for the remaining values in the table:

I hope you’re intrigued to explore more about this probability function. We can’t rely on a brute force analysis any further, so we’ll do some math to figure out the general case in the next post. We’ll also practice applying the optimal strategy on the 12-candidate case, and we’ll extend this probability function as far as 5000 candidates. This will provide a strong hint of the Remarkable Result to come.