#65 Matching variables to graphs
On Friday of last week I asked my students to engage with an activity in which I presented them with these seven graphs:

I’m sure you’ve noticed that these graphs include no labels or scales on the axes. But you can still discern some things about these seven distributions even without that crucial information. I told my students the seven variables whose distributions are displayed in these graphs:
- (A) point values of letters in the board game Scrabble
- (B) prices of properties on the Monopoly game board
- (C) jersey numbers of Cal Poly football players
- (D) weights of rowers on the U.S. men’s Olympic team
- (E) blood pressure measurements for a sample of healthy adults
- (F) quiz percentages for a class of students (quizzes were quite straight-forward)
- (G) annual snowfall amounts for a sample of cities taken from around the U.S.
But I did not tell students which variable goes with which graph. Instead I asked them to work in groups* with these instructions: Make educated guesses for which variable goes with which graph. Be prepared to explain the reasoning behind your selections.
* This being the year 2020, the students’ groups were breakout rooms in Zoom.
Before I invited the students to join breakout rooms, I emphasized that it’s perfectly fine if they know nothing about Scrabble or Monopoly or rowing or even snowfall*. For one thing, that’s why they’re working with a group. Maybe they know about some of these things and a teammate knows about others. For another thing, I do not expect every group to match all seven pairs perfectly, and this activity is not graded.
* Most of my students are natives of California, and some have never seen snowfall.
I think you can anticipate the next sentence of this blog post: Please take a few minutes to match up the graphs and variables for yourself before you read on*.
* Don’t worry, I do not expect you to get them all right, and remember – this is not for a grade!
Also before I continue, I want to acknowledge that I adapted this activity from Activity-Based Statistics, a wonderful collection based on an NSF-funded project led by Dick Scheaffer in the 1990s. This variation is also strongly influenced by Beth Chance’s earlier adaptations of this activity, which included generating the graphs from data collected from her students on various variables.
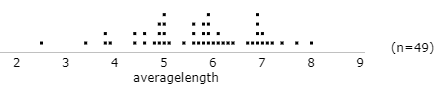
I only gave my students 5-6 minutes to discuss this in their breakout rooms. When they came back to the main Zoom session, I asked for a volunteer to suggest one graph/variable pair that they were nearly certain about, maybe even enough to wager tuition money. The response is always the same: Graph #4 displays the distribution of football players’ jersey numbers. I said this is a great answer, and it’s also the correct answer, but then I asked: What’s your reasoning for that? One student pointed out that there are no repeated values, which is important because every player has a distinct jersey number. Another student noted that there are a lot of dots, which is appropriate because college football teams have a lot of players.
Next I asked for another volunteer to indicate a pairing for which they are quite confident, perhaps enough to wager lunch money. I received two different answers to this. In one session, a student offered that graph #1 represents the quiz percentages. What’s your reasoning for that? The student argued that quizzes were generally straight-forward, so there should be predominatly high scores. The right side of graph #1 could be quiz percentages in the 80s and 90s, with just a few low values on the left side.
In the other session, a student suggested that graph #2 goes with point values of letters in Scrabble. What’s your reasoning for that? The student noticed that the spacing between dots on the graph is very consistent, so the values could very well be integers. It also makes sense that the leftmost value on the graph could be 1, because many letters are worth just 1 point in Scrabble. This scale would mean that the large values on the right side of the graph are 8 (for 2 letters) and 10 (also for 2 letters). Another student even noted that there are 26 dots in graph #2, which matches up with 26 letters in the alphabet.
When I asked for another volunteer, a student suggested that graph #7 corresponds to Monopoly prices. What’s your reasoning for that? The student commented that Monopoly properties often come in pairs, and this graph includes many instances of two dots at the same value. Also, the distance between the dots is mostly uniform, suggesting a common increment between property prices. I asked about the largest value on this graph, which is separated a good bit from the others, and a student responded that this dot represents Boardwalk.
After those four variables and graphs were matched up, students got much quieter when I asked for another volunteer. I wish that I had set up a Zoom poll in advance to ask them to express their guesses for the rest, but I did not think of that before class. Instead I asked for a description of graph #3. A student said that there are a lot of identical values on the low end, and then a lot of different values through the high end. When I asked about which variable that pattern of variation might make sense for, a student suggested snowfall amounts. What’s your reasoning for that? The student wisely pointed out that I had said that the cities were taken from around the U.S., so that should include cities such as Los Angeles and Miami that see no snow whatsoever.
Then I noted that the only graphs left were #5 and #6, and the only variables remaining were blood pressure measurements and rower weights. I asked for a student to describe some differences between these graphs to help us decide which is which. This is a hard question, so I pointed out that the smallest value in graph #6 is considerably smaller than all of the others, and there’s also a cluster of six dots fairly well separated from the rest in graph #6. One student correctly guessed that graph #6 displays the distribution of rower weights. What’s your reasoning for that? The student knew enough about rowing to say that one member of the team calls out the instructions to help the others row in synch, without actually rowing himself. Why does the team want that person to be very light? Because he’s adding weight to the boat but not helping to row!
That leaves graph #5 for the blood pressure measurements. I suggested that graph #5 is fairly unremarkable and that points are clustered near the center more than on the extremes.
You might be wondering why I avoided using the terms skewness, symmetry, and even outlier in my descriptions above. That’s because I introduced students to these terms at the conclusion of this activity. Then I asked students to look back over the graphs and: Identify which distributions are skewed to the left, which are skewed to the right, and which are roughly symmetric. I gave them just three minutes to do this in the same breakout rooms as before. Some students understandably confused skewed to the left and skewed to the right at first, but they quickly caught on. We reached a consensus as follows:
- Skewed to the left: quiz percentages (sharply skewed), rower weights (#1, #6)
- Skewed to the right: Scrabble points, snowfall amounts (#2, #3)
- Symmetric (roughly): jersey numbers, blood pressure measurements, Monopoly prices (#4, #5, #7)
I admitted to my students that while I think this activity is very worthwhile, it’s somewhat contrived in that we don’t actually start a data analysis project by making guesses about what information a graph displays. In practice we know the context of the data that we are studying, and we produce well-labelled graphs that convey the context to others. Then we examine the graphs to see what insights they provide about the data in context.
With that in mind, I followed the matching activity with a brief example based on the following graph of predicted high temperatures for cities around California, as I found them in my local newspaper (San Luis Obispo Tribune) on July 8, 2012:

I started with some basic questions about reading a histogram, such as what temperatures are contained in the rightmost bin and how many cities had such temperatures on that date. Then I posed three questions that get to the heart of what this graph reveals:
- What is the shape of this distribution?
- What does this shape reveal about high temperatures in California in July?
- Suggest an explanation for the shape of this distribution, using what you know about the context.
Students responded that the temperature distribution displays a bimodal shape, with one cluster of cities around 65-80 degrees and another cluster from about 90-100 degrees. This reveals that California has at least two distinct kinds of locations with regard to high temperatures in July.
For the explanation of this phenomenon, a student suggested that there’s a split between northern California and southern California. I replied that this was a good observation, but I questioned how this split would produce the two clusters of temperature values that we see in the graph. The student quickly followed up with a different explanation that is spot-on: California has many cities near the coast and many that are inland. How would this explain the bimodality in the graph? The student elaborated that cities near the coast stay fairly cool even in July, while inland and desert cities are extremely hot.
My students and I then worked through three more examples to complete the one-hour session. Next I showed them the following boxplots of daily high temperatures in February and July of 2019 for four cities*:

* I discuss these data in more detail in post #7, Two dreaded words, part 2, here.
The students went back to their breakout rooms with their task to: Arrange these four cities from smallest to largest in terms of:
- center of February temperature distributions;
- center of July temperature distributions;
- variability of February temperature distributions; and
- variability of July temperature distributions
After we discussed their answers and reached a consensus, I then briefly introduced the idea of a log transformation in the context of closing prices of Nasdaq-100 stocks on September 15, 2020:

Finally, we discussed the example of cancer pamphlets’ readability that I described in post #4, Statistics of illumination, part 2, here.
As you can tell, the topic of the class session that I have described here was graphing numerical data. I think the matching activity set the stage well, providing an opportunity for students to talk with each other about data in a fun way. I also hope that this activity helped to instill in students a mindset that they should always think about context when examining graphs and analyzing data.