#56 Two questions to ask before making causal conclusions
This guest post has been contributed by Kari Lock Morgan. You can contact her at klm47@psu.edu.
Kari Lock Morgan teaches statistics at Penn State. Along with other members of her family, she is co-author of Statistics: Unlocking the Power of Data, an introductory textbook that emphasizes simulation-based inference. Kari is an excellent and dynamic presenter of statistical ideas for both students and teachers. She gave a terrific presentation about evaluating causal evidence at the 2019 U.S. Conference on Teaching Statistics (a recording of which is available here), and I greatly appreciate Kari’s sharing some of her ideas as a guest blog post.
* I always implore students to read carefully to notice that causal is not casual.
How do we get introductory students to start thinking critically about evaluating causal evidence? I think we can start by teaching them to ask good questions about potential explanations competing with the true causal explanation.
Let’s start with a generic example. (Don’t worry, we’ll add context soon, but for now just fill in your favorite two group comparison!). Suppose we are comparing group A versus group B (A and B could be two treatments, two levels of an explanatory variable, etc.). Suppose that in our sample, the A group has better outcomes than the B group. I ask my students to brainstorm about: What are some possible explanations for this? As we discuss their ideas, I look for (and try to tease out) three possible explanations:
- Just random chance (no real association)
- The A group differed from the B group to begin with (association, but due to confounding)
- A causes better outcomes than B (causal association)
This framework then leads naturally into what I think are the two key questions students should ask and answer when evaluating causal evidence:
- Key question 1: Do we have convincing evidence against “just random chance”? Why or why not?
- Key question 2: Do we have convincing evidence against the groups differing to being with? Why or why not?
If the answers to both of the above questions are “yes,” then we can effectively eliminate the first two alternatives in favor of the true causal explanation. If the answer to either of the above questions is “no,” then we are left with competing explanations and cannot determine whether a true causal association exists.
As teachers of introductory statistics, where do we come in?
- Step 1: We have to help students understand why each of these questions is important to ask.
- Step 2: We have to help students learn how to answer these questions intelligently.
As a concrete example, let’s look at the health benefits of eating organic. We’ll investigate this question with two different datasets:
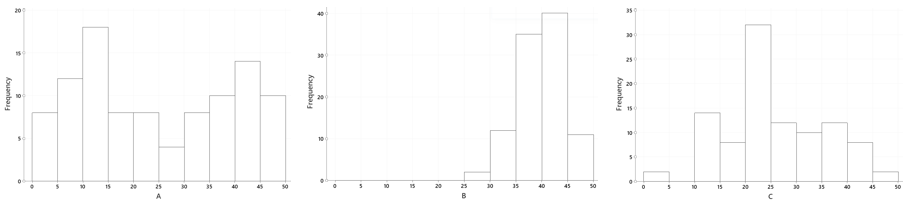
1. Data from the National Health and Nutrition Examination Survey (NHANES), a large national random sample. Our explanatory variable is whether or not the respondent bought anything with the word organic on the label in the past 30 days, and the response variable is a dichotomized version of self-reported health status: poor/fair/good versus very good/excellent. The sample data are visualized below:
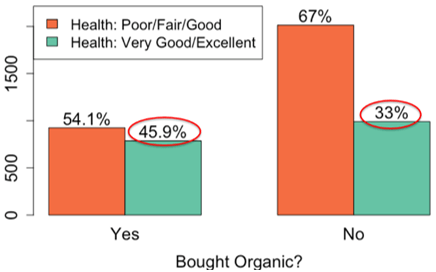
In the sample, 45.9% of organic buyers had very good or excellent health, as compared to only 33% of people who hadn’t bought organic, for a difference in proportions of 0.459 – 0.33 = 0.129.
In the second dataset, fruit flies were randomly divided into two groups of 1000 each; one group was fed organic food and the other group was fed conventional (non-organic) food*. The longevity of each fly by group is visualized below:
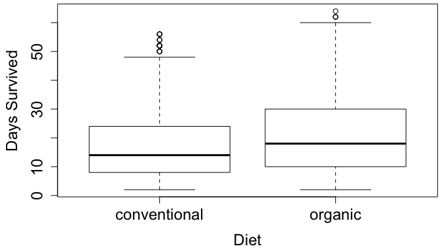
* Fun fact: This study was conducted by a high school student! The research article is available here.
Organic-fed flies lived an average of 20.31 days, as compared to an average of 17.06 days for conventional-fed flies, giving a difference in means of 3.25 days (which is long in the lifespan of a fruit fly!).
In both of these datasets, the organic group had better outcomes than the non-organic group. What are the possible explanations?
- Just random chance (no real association)
- The organic group differed from the non-organic group to begin with (association, but due to confounding)
- Eating organic causes better health status/longevity than not eating organic (causal association)
Do we have convincing evidence against alternative explanations (1) and (2)? How can we decide?
As I mentioned above, we teachers of introductory statistics have two jobs for each of these questions: first helping students understand why the question needs to be asked, and then helping students learn how to answer the question. I’ll address these in that order:
STEP 1: Help students understand why each of the key questions is important to ask – why it’s important to consider them as potential competing explanations for why outcomes may be higher in one group than another. (This is non-trivial!)
Key question 1: Do we have convincing evidence against “just random chance”? Why or why not?
Why is this question needed? We have to take the time to help students understand – deeply understand – the idea of statistical inference, at its most fundamental level. Results vary from sample to sample. Just because a sample statistic is above 0 (for example) doesn’t necessarily imply the same for the population parameter or the underlying truth. This is NOT about illustrating the Central Limit Theorem and deriving the theoretical distribution for a sample mean – it is about illustrating to students the inherent variability in sample statistics. While this can be illustrated directly from sample data, I think this is best conveyed when we actually have a population to sample from and know the underlying truth (which isn’t true for either of the datasets examined here).
Key question 2: Do we have convincing evidence against the groups differing to being with? Why or why not?
Why is this question needed? We have to take the time to help students understand – deeply understand – the idea of confounding, and why it’s dangerous to jump straight to the causal explanation if the groups differ to begin with. If the groups differ to begin with, we have no way of knowing whether this baseline difference or the A versus B distinction is causing the better outcomes. I think that both talking through intuitive examples* and showing them real examples with measured data on the confounding variableare both important to help students grapple with this concept. This is, inherently, reliant on multivariable thinking, and examples must go beyond bivariate context.
* See posts #43 and #44 (here and here) for several examples.
In our NHANES organic example, I ask students to brainstorm: How might people who buy organic differ from the non-organic buyers? Intuition is easy here, and students are good at this! A common student answer is income, because organic food is more expensive. I respond by showing a real-data visualization of the relationship between eating organic and income, and between income and health status:
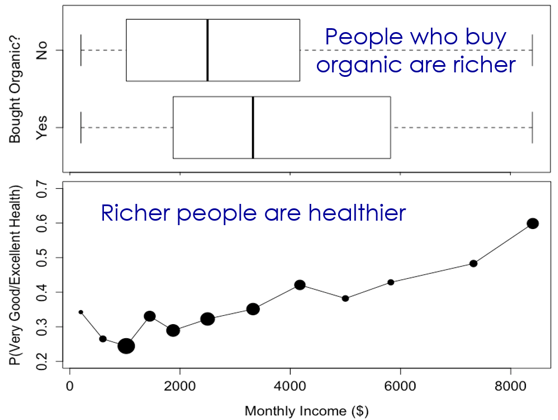
The sample data reveal that people who buy organic are richer, and richer people are healthier, so we would expect organic buyers to be healthier, even if buying organic food provided no real health benefit. This is a concrete example of confounding, one that students can grasp. Of course, income is not the only difference between people who buy organic and those who don’t, as students are quick to point out. Given all of the differences, it is impossible to determine whether the better health statuses among organic buyers are actually due to buying organic food, or simply to other ways in which the groups differ.
The key takeaway is that directly comparing non-comparable groups cannot yield causal conclusions; thus it is essential to think about whether the groups are comparable to begin with.
STEP 2: Help students learn how to reason intelligently about each of the key questions.
Key question 1: Do we have convincing evidence against “just random chance”? Why or why not?
While we can assess this with any hypothesis test, I strongly believe that the most natural and intuitive way to help students learn to reason intelligently about this question is via simulation-based inference*. We can directly simulate the values of statistics we would expect to see, just by random chance. Once we have this collection of statistics, it’s relatively straightforward to assess whether we would expect to see the observed value of the sample statistic, just by random chance.
* See posts #12, #27, and #45 (here, here, and here) for more on simulation-based inference.
I suggest that we can help students to initially reason about this in very extreme examples where a visual assessment is sufficient:
- either the value of the sample statistic is close to the middle of the distribution of simulated statistics: could easily see such a statistic just by chance, so no, we don’t have convincing evidence against just random chance; or
- the value of the sample statistic is way out in the tail: it would be very unlikely to see such a statistic just by chance, so yes, we have convincing evidence against just random chance.
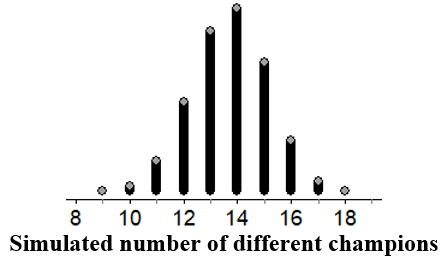
In the case of the organic fruit flies dataset, we can use StatKey (here) to obtain the following distribution of simulated differences in sample means:
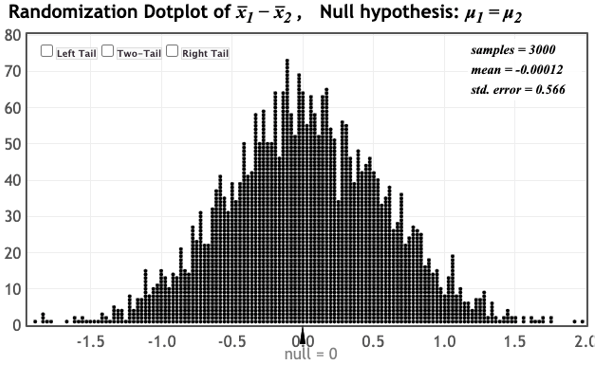
We notice that the observed difference in sample means of 3.25 days is nowhere to be seen on this distribution, and hence very unlikely to occur just by random chance. (The sample statistic is even farther out in the tail for the NHANES dataset.) We have convincing evidence against just random chance!
Of course, not all examples are extreme one way or another, so eventually we quantify this extremity with the p-value (a natural concept once we have students thinking this way!), but this quantification can follow after developing the intuition of “would I expect a sample statistic this extreme just by chance?”.
Key question 2: Do we have convincing evidence against the groups differing to being with? Why or why not?
The best evidence against the groups differing to begin with is the use of random assignment to groups. If the groups are randomly assigned, those groups should be similar regarding both observed and unobserved variables! Although some differences may persist, any differences are purely random (by definition!). You can simulate random assignment to convince students of this, which also makes a nice precursor to simulation-based inference!.
Random assignment is not just an important part of study design, but a key feature to check for when evaluating causal evidence. If my introductory students take only one thing away from my course, I want them to know to check for random assignment when evaluating causal evidence, and to know that random assignment is the best evidence against groups differing to begin with.
Because the fruit flies were randomly assigned to receive either organic or non-organic food, we have convincing evidence against groups differing to begin with! For the fruit flies we’ve now ruled out both competing explanations, and are left with the causal explanation – we have convincing evidence that eating organic really does cause fruit flies to live longer!! Time to go buy some organic food*!!
* If you’re a fruit fly.
Because the NHANES respondents were not randomly assigned to buy organic food or not, it’s not surprising that we do observe substantial differences between the groups, and we would suspect differences even if we could not observe them directly. This doesn’t mean that buying organic food doesn’t improve health status*, but this does mean that we cannot jump to the causal conclusion from these data alone. We have no way of knowing whether the observed differences in reported health were due to a causal effect of buying organic food or due to the fact that the organic buyers differed from non-organic buyers to begin with.
* Make sure that students notice the double negative there.
Now I’ll offer some extra tidbits for those who want to know more about questioning causal conclusions.
When thinking about key question #2 about the groups differing to begin with, I want introductory students to understand (a) why we can’t make causal conclusions when comparing groups that differ to begin with, (b) without random assignment, groups will almost always naturally differ to begin with, and (c) with random assignment groups will probably look pretty similar. These are important enough concepts that I try not to muddy them too much in an introductory course, but in reality it’s possible (in some situations) to create similar groups without randomization, and it’s also possible to obtain groups that differ even after randomization, just by chance.
Random assignment is not the only way to rule out groups differing to begin with; one could also collect data on all possible confounding variables (hard!) and force balance on them such as with propensity score matching or subclassification, but this is beyond the scope of an introductory course. If you want to move towards this idea, you could compare units within similar values of an observed confounder (stratification). For example, in the NHANES example, the organic buyers were healthier even compared to non-organic buyers within the same income bracket:
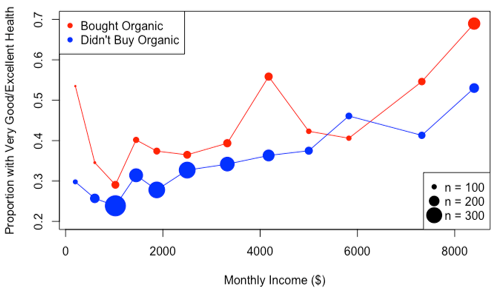
However, while this means the observed difference is not solely due to income, we still cannot rule out the countless other ways in which organic eaters differ from non-organic eaters. We could extend this to balance multiple variables by stratifying by the propensity score, the probability of being in one group given all measured baseline variables (it can be estimated by logistic regression). While this is a very powerful tool for making groups similar regarding all observed variables, it still can’t do anything to balance unobserved variables, leaving random assignment as the vastly superior option whenever possible.
While random assignment creates groups that are similar on average, in any particular randomization groups may differ just due to random variation. In fact, my Ph.D. dissertation was on rerandomization – the idea that you can, and should, rerandomize (if you do it in a principled way) if randomization alone does not yield adequate balance between the groups. In an introductory course, we can touch on some classical experimental designs aimed to help create groups even more similar than pure randomization, for example, by randomizing within similar blocks or pairs. One classic example is identical twin studies, which I can’t resist closing with because I can show a picture of my identical twin sons Cal and Axel in their treatment and control shirts!

Questioning causal evidence involves evaluating evidence against competing explanations by asking the following key questions:
- Do we have convincing evidence against “just random chance”? Why or why not?
- Do we have convincing evidence against the groups differing to being with? Why or why not?
By the time students finish my introductory course, I hope that they have internalized both of these key questions –both why the questions need to be asked when evaluating causal evidence, and also how to answer them.
P.S. Below are links to datafiles for the examples in this post:
This guest post has been contributed by Kari Lock Morgan. You can contact her at klm47@psu.edu.