#82 Power, part 3
This post continues and completes my discussion of introducing students to the concept of power. Let me remind you of the scenario that I presented in the first post of this series (here):
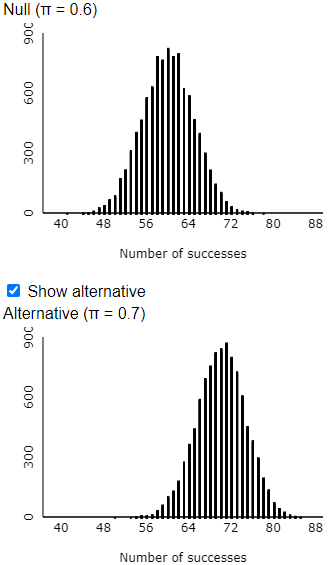
Suppose that Tamika is a basketball player whose probability of successfully making a free throw has been 0.6. During one off-season, she works hard to improve her probability of success. Of course, her coach wants to see evidence of her improvement, so he asks her to shoot some free throws. If Tamika really has improved, how likely is she to convince the coach that she has improved?
The first post in this series described using an applet (here) to conduct simulation analyses to lead students to the concepts of rejection region and power, and then to consider factors that affect power. In this post I will make three points about teaching these concepts in courses for mathematically inclined students, such as those majoring in statistics or mathematics or engineering or economics.
1. Start with simulation analyses, even for mathematically inclined students.
I suspect that some statistics teachers regard simulation as a valuable tool for students who are uncomfortable with math but not necessarily with mathematically inclined students. I agree I think simulation can be very enlightening and powerful tools even with students who enjoy and excel at mathematical aspects of statistics. I recommend introducing students to the concept of power through simulation analyses, regardless of how well prepared or comfortable the students are with mathematics.
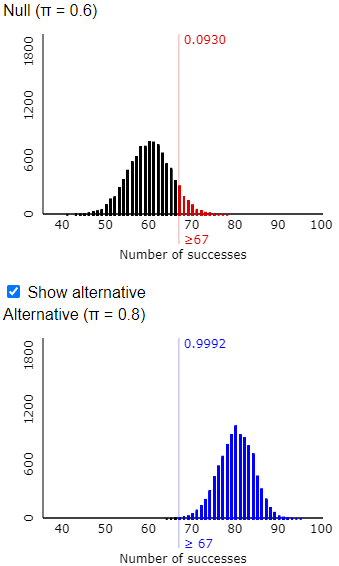
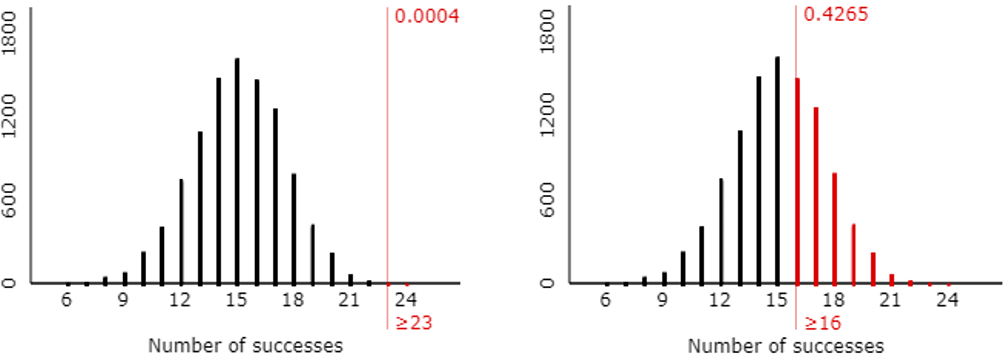
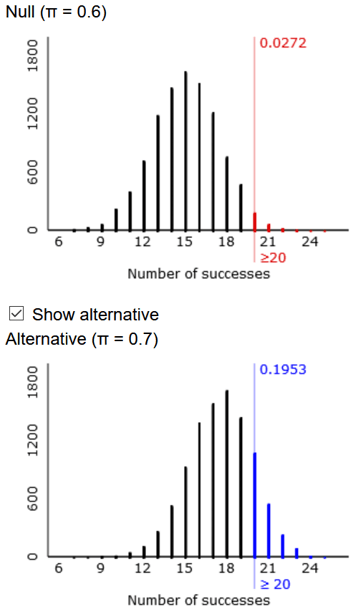
You could ask students to write their own code to conduct these simulations, but I typically stick with the applet because it’s so convenient and produces nice visuals such as:
2. Proceed to ask mathematically inclined students to perform probability calculations to confirm what the simulations reveal.
Tamika’s example provides a great opportunity for students to practice working with the binomial distribution:
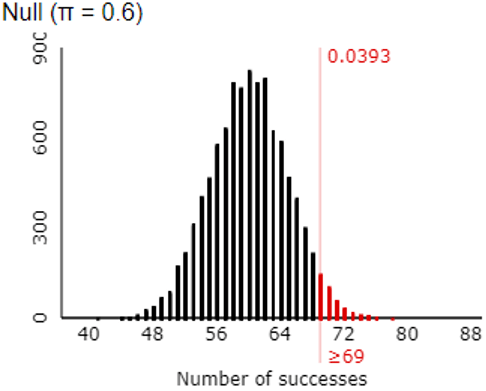
- a) Let the random variable X represent the number of shots that Tamika would successfully make out of 25 shots, assuming that she has not improved. What probability distribution would X have?
- b) Determine the smallest value of k for which Pr(X ≥ k) ≤ 0.05.
- c) Does this agree with your finding from the simulation analysis?
- d) Explain what this number has to do with Tamika’s efforts to convince the coach that she has improved.
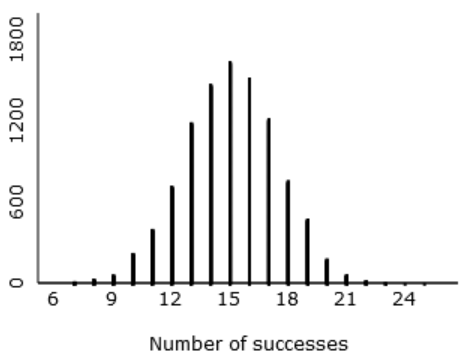
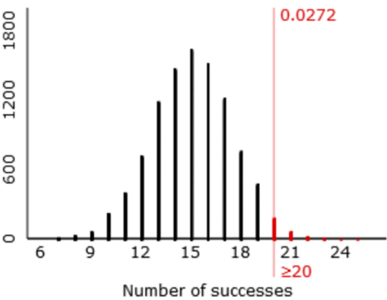
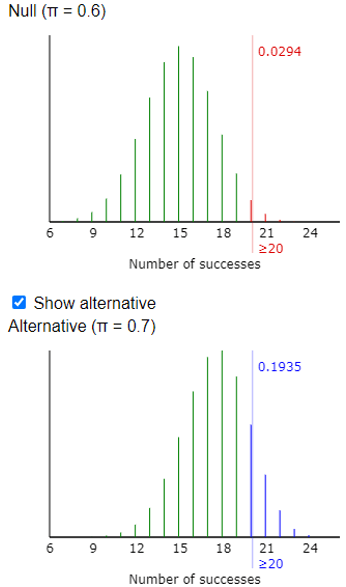
The random variable X would have a binomial distribution with n = 25 and p = 0.6. To answer part (b), students could work with a cumulative distribution function by realizing that Pr(X ≥ k) = 1 – Pr(X ≤ k – 1) in this case. Then they can use software or a graphing calculator to determine that the smallest value of k that satisfies this criterion is k = 20, for which Pr(X ≥ 20) ≈ 0.0294. This means that Tamika must successfully make 20 or more of the 25 shots to convince her coach that she has improved, when the coach gives her 25 shots and using 0.05 as his standard to be convinced.
Instead of using the cumulative distribution function, students could use the inverse cumulative distribution function built into many software programs. For example, this command in R is:
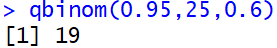
Some students get tripped up by the need for the first input to be 0.95 rather than 0.05. Students also need to be careful to realize that the output value of 19 = k – 1, so the value of k = 20. As some students struggle with this, I remind them of two things: First, they should return to their simulation results to make sure that their binomial calculations agree. Second, when they’re not sure whether 19 or 20 is the answer they’re looking for, they can check that by calculating Pr(X ≥ 19) and Pr(X ≥ 20) to see which one meets the criterion.
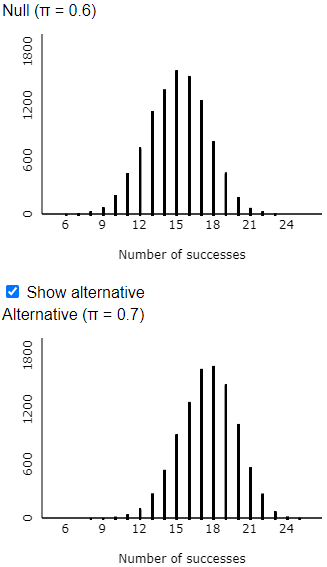
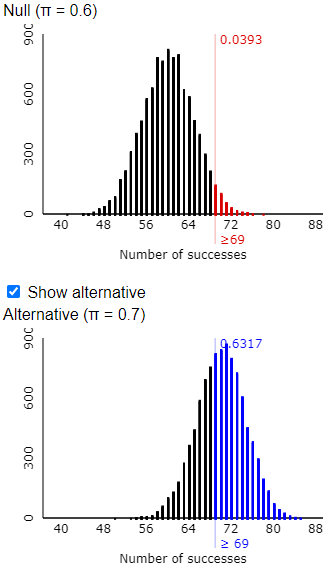
- e) Let the random variable Y represent the number of shots that Tamika would successfully make if she has improved her success probability to 0.7. What probability distribution would Y have?
- f) Determine Pr(Y ≥ k) for the value of k that you determined in part (b).
- g) Does this agree with your finding from the simulation analysis?
- h) Explain what this number has to do with Tamika’s efforts to convince the coach that she has improved.
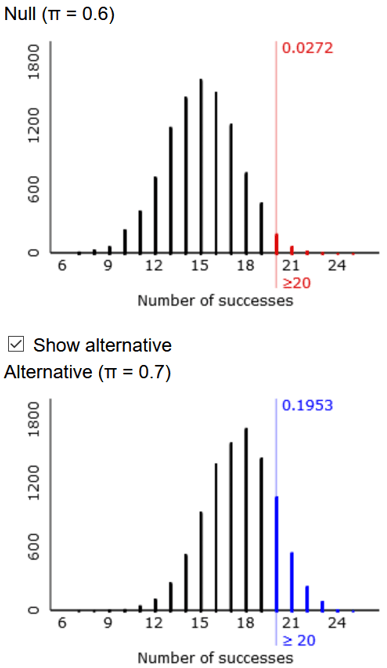
The random variable Y would have a binomial distribution with n = 25 and p = 0.7. Once they realize this, students can use software to calculate Pr(Y ≥ 20) ≈ 0.1935. For example, the R command to calculate this is:

This probability is very close to the approximation from the simulation analysis. Tamika has slightly less than a 20% chance of convincing her coach that she has improved, if she is given a sample of 25 shots, the coach uses a significance level of 0.05, and her improved probability of success is 0.7 rather than 0.6.
Students can then use software to produce exact power calculations, using the binomial probability distribution, for different values of the sample size, significance level, and improved success probability.
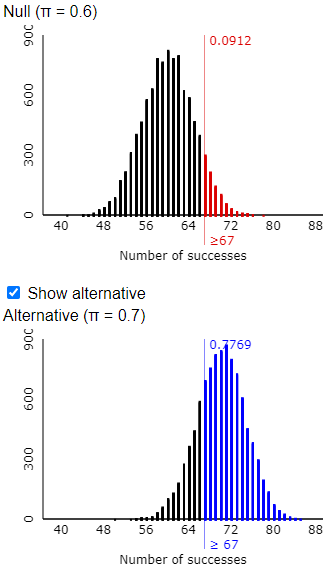
A drawback of using software such as R or Excel to calculate these probabilities is that they do not automatically provide visual representation of the probability distribution. The applet that I used for the simulation analyses does have an option to calculate and display exact binomial probabilities:
3. Ask mathematically inclined students to write code to produce graphs of power as a function of sample size, or significance level, and of alternative value for the parameter.
Recall that the pair of R commands for calculating the rejection region and power for Tamika’s first situation is:

Then I like to ask mathematically included students: Re-write this power calculation to use just one line of code. For students who need a hint: Where did the 19 value in the second line come from? This leads to:
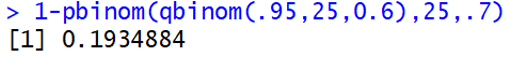
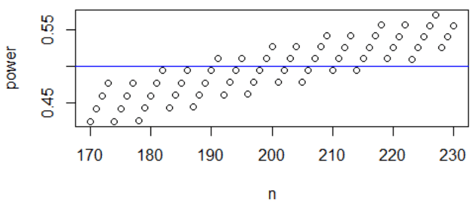
A follow-up is: How can you alter this command to calculate power as a function of sample size, for values from n = 1 through n = 300? The key is to replace the value 25 with a vector (call it n) containing integer values from 1 through 300. The resulting graph (with α = 0.05 and palt = 0.7) is:
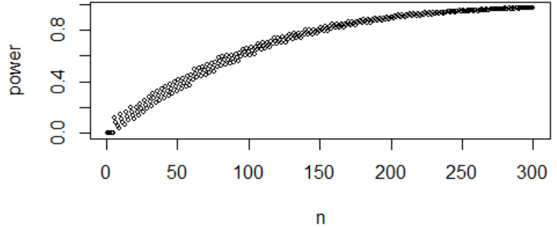
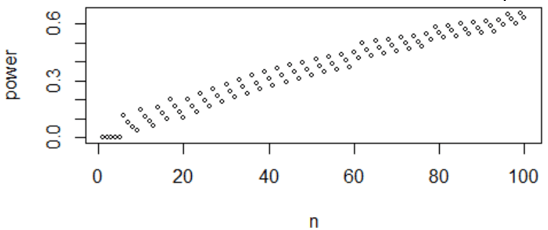
Does this graph behave as you expected? Mostly yes, but there’s an oddity. This graph shows that power generally increases as sample size increases, as we expected. But I say generally because there are lots of short-run exceptions, because of the discrete-ness of the binomial distribution. The pattern is more noticeable if we restrict our attention to sample sizes values from n = 1 through 100:
Students can then proceed to produce and describe graphs of power as a function of significance level and of the improved probability value (for n = 25 in both graphs, palt = 0.7 on the left, and α= 0.05 on the right), as shown here:
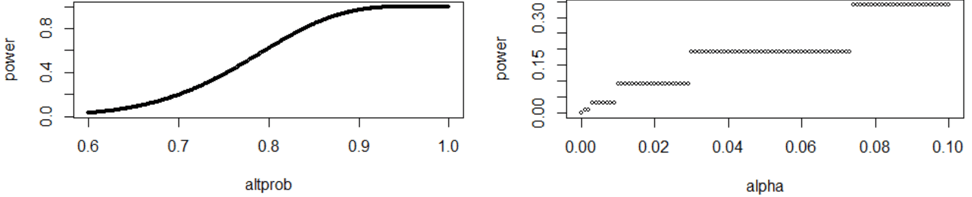
Do these graphs behave as you expected? Power increases as the significance level increases, as expected, but this is a step function due to the discreteness. Power does increase as the improved probability value increases, as expected.
The concept of power is a challenging one for many students to grasp. I recommend starting with a simple scenario involving a single proportion, such as Tamika trying to convince her coach of her improvement as a free throw shooter. I think simulation analyses and visualizations can help students to understand the key ideas*. With mathematically inclined students, I suggest following up the simulations with probability calculations and simple coding as described in this post. My hope is that these activities deepen their understanding of power and also their facility with probability distributions.
* As long as the simulation analyses are accompanied by asking good questions!