#24 Random rendezvous, part 2
In last week’s post (here), I described one of my favorite probability problems: Two people plan to meet for lunch, their arrival times are independent and uniformly distributed over an hour, and they agree to wait fifteen minutes for the other to arrive. I ask my students to determine the probability that they successfully meet, first using intuition, then simulation, and finally mathematics.
This post will consider a modification to this problem: Suppose that the arrival times follow normal (Gaussian) rather than uniform distributions. Again I ask a series of questions that lead my students to tackle this extension with intuition, simulation, and mathematics. Now the necessary mathematics will involve properties of random variables rather than geometry. (As always, questions for students appear in italics.)
Let’s name this week’s lunch companions Michael and LeBron. Just like Eponine and Cosette last week, they agree to wait 15 minutes for the other to arrive. Suppose that Michael and LeBron’s arrival times at the restaurant follow independent normal distributions, each with mean 30 minutes (after noon) and standard deviation 10 minutes. First I ask students to think about this scenario and make some predictions:
- Do you think Michael and LeBron are more likely, less likely, or equally likely to successfully meet, as compared to Eponine and Cosette whose arrival times were uniform between noon and 1pm?
- Make a guess for the probability that Michael and LeBron successfully meet.
- Draw a rough sketch of what you expect the joint distribution of their arrival times to look like.
Then I ask: How can we investigate the joint distribution of their arrival times and approximate the probability that they successfully meet? I hope that the class erupts in response with a chorus of: Simulate!
Let’s begin the simulation analysis by asking: What lines of code do we need to change from last week’s simulation analysis? I think it’s fair to ask this of students even If they have no coding experience themselves. If they need a hint: What was the name of the probability distribution of the arrival times last week? The only lines of code that need changing are the ones for simulating uniformly distributed arrival times (on the left below, where N represents the number of repetitions), and you can show them the new code to simulate normally distributed arrival times (on the right):

Other than this change, the rest of the program used for last week’s analysis (see the end of that post here) can be used without modification. Before running the code, I ask: What do you expect the distributions of arrival times, difference in arrival times, and absolute difference in arrival times to look like? Running the code for 10,000 repetitions produces results such as:
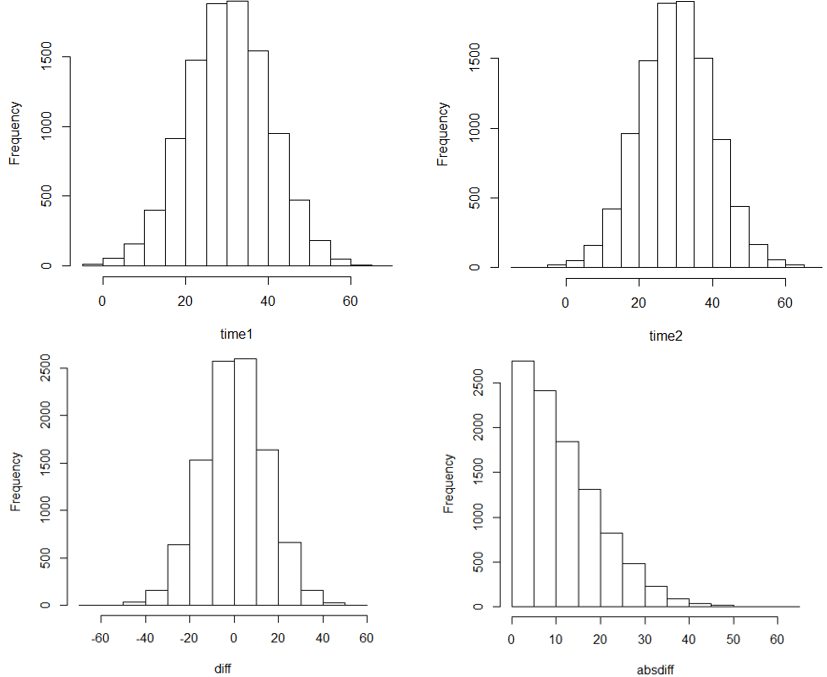
Describe what these graphs reveal. As expected, the distributions of arrival times closely resemble normal distributions, centered around 30 minutes, with almost all the times between 0 and 60 minutes (after noon). The distribution of differences in arrival times also appears to follow a normal distribution, with a mean close to 0 minutes and most values between -40 and 40 minutes. The distribution of absolute differences is sharply skewed to the right, centered around 10 minutes or so.
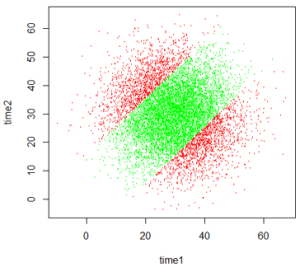
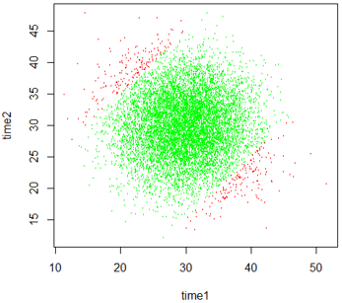
The most informative graph is a scatterplot of arrival times, coded by whether a successful meeting occurs (green for yes, red for no). What do you expect the scatterplot to look like? How (if at all) will it differ from the scatterplot when we assumed uniform distributions for arrival times? Here is a result from 10,000 repetitions:
How is this joint distribution different from the case with uniform arrival times? These (joint) arrival times are not evenly spread out throughout a 60×60 square. Instead they are concentrated around the point (30,30), and they become gradually less dense as they move away from that center point in any direction.
How does the region of arrival times for which they successfully meet compare to the uniform case? The successful meetings, coded in green, occur within 15 minutes on either side of the y = x diagonal line. It looks like more than half of the dots are green, signaling successful meetings, but it’s hard to tell from the graph. We need to count how many of the 10,000 repetitions resulted in success. For these 10,000 repetitions we obtain:

Use a margin-of-error to calculate a 95% confidence interval for the exact probability. The margin-of-error is approximately 1/sqrt(10,000) = .01, so we can be about 95% confident that the exact probability of a successful meeting is between ( .7071 → .7271).
Now suppose that Michael and LeBron want to increase their chance of successfully meeting to 90%. Would they need to wait for more or less than 15 minutes? Explain. Nearly all students realize that they’ll need to increase their waiting time to more than 15 minutes in order to increase their probability of a successful meeting.
How can you use your simulation results to approximate how many minutes they need to wait to have a 90% chance of meeting? This question is harder than a similar one in the previous post about a 50% chance of meeting. In that case we simply calculated the median of the 10,000 simulated values for the absolute difference in arrival times. But the same idea will work here: instead of the 50th percentile we need to determine the 90th percentile of the absolute differences. We can use R to do this by sorting the vector of absolute differences and then picking out the 9000th value among the 10,000 simulated values in that sorted vector:

We can approximate that Michael and LeBron should agree to wait for a bit more than 23 minutes in order to have a 90% chance of successfully meeting.
Now let’s turn to a mathematical solution. We cannot use geometry as we did when the arrival times followed uniform distributions (here), because the (joint) arrival times are not equally likely to fall throughout the 60×60 square. The key now is to use properties of random variables.
Let’s introduce some notation: Let the random variable X represent Michael’s arrival time and Y represent LeBron’s arrival time. Express the probability of a successful meeting in terms of these random variables. We can see from the labeled scatterplot of simulation results above that they successfully meet when their arrival times are within 15 minutes of each other, so we want Pr(|X – Y| < 15).
The bad news is that it’s not easy to determine the probability distribution of the absolute difference |X – Y|. But the good news is that we can use probability rules to determine the distribution of the difference (X – Y). Rewrite the probability of a successful meeting without the absolute value. This is a challenging part for many students, who need to recall how to work with inequalities involving absolute values. We can re-express Pr(|X – Y| < 15) as Pr(-15 < X – Y < 15).
Determine the name and parameter values of the probability distribution of the difference in arrival times (X – Y). The first rule we need is that the sum or difference (or any linear combination) of normally distributed random variables also follows a normal distribution. Then we can determine the mean, variance, and standard deviation of (X – Y) as follows:
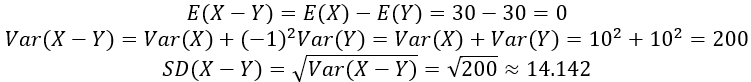
As a way to check their work, and as a good practice to model for students, I ask: Calculate the mean and SD of the 10,000 simulated differences. Are they close to these theoretical values? Students find that the simulation did produce reasonable approximations, helping to confirm that these theoretical calculations are correct.
Now we have a straightforward normal probability calculation. We could calculate z-scores (they turn out to be z ≈ ± 1.06) and use a normal probability table, or we could use an applet (here, output shown below), or we could use R (output shown further below):
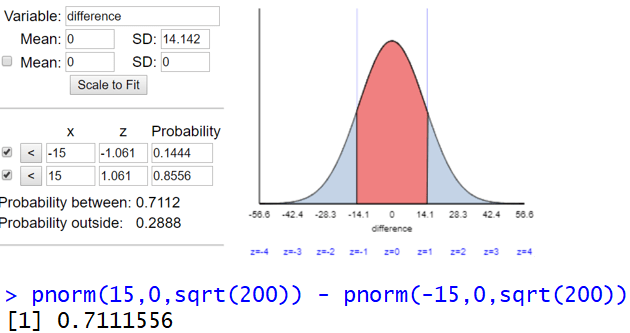
We see that Michael and LeBron have a 71.12% probability of meeting successfully. Is the theoretical probability from the normal distribution within the margin-of-error of the approximate probability from the simulation analysis? Yes, because 0.7112 is within the interval ( .7071 → .7271) that we calculated from the simulation.
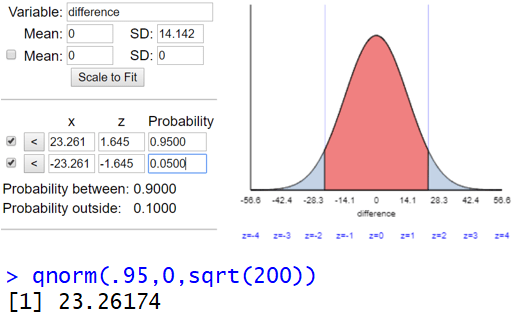
Use the normal distribution to determine how long Michael and LeBron must agree to wait in order to have a 90% chance of meeting. We need to calculate the 5th and 95th percentiles of the (normal) distribution of the difference (X – Y). We could use an applet or R (see output below), or we could realize that the relevant z-scores are z = ±1.645. The necessary waiting time is therefore 1.645 standard deviations above the mean: 0 + 1.645×14.142 ≈ 23.264 minutes. Once again I ask: Compare this to the approximate value that we determined from simulation. This is quite close to the approximate value of 23.132 minutes that we found with simulation.
A natural extension is to investigate the effect of changing the means and/or standard deviations of the arrival times. For example: Suppose that Michael and LeBron could make their arrival times more consistent by reducing their standard deviations from 10 to 5 minutes. How would this change the probability that they successfully meet? First predict, then simulate, then use mathematics.
Intuition: Most students realize that with less variability (more consistency) in their arrival times, Michael and LeBron are more likely to meet than they were before.
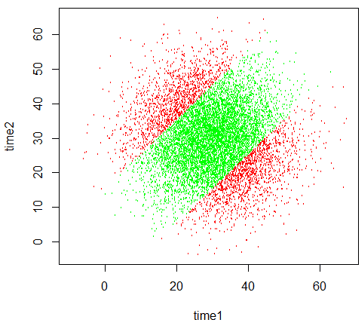
Simulation: A simulation analysis with the smaller standard deviations produces a graph such as the one below. The arrival times are much less spread out than before, with almost all arrival times between 15 and 45 minutes (after noon), so Michael and LeBron are much more likely to meet.
Mathematics: The standard deviation of the difference (X – Y) becomes sqrt(5^2+5^2) = sqrt(50) ≈ 7.071 minutes. Then Pr(-15 < (X – Y) < 15) becomes ≈ 0.9661 (z-scores are ±2.12). As expected, this probability is a considerably larger, because of the smaller standard deviations of arrival times, than with the original scenario.
Ready for a more complicated extension? The calculations for this one go beyond the scope of most introductory statistics courses. Nevertheless, the intuition here should make sense for introductory students. How would you expect the probability of successfully meeting to change if Michael and LeBron’s arrival times are not independent but rather are positively correlated? What if their arrival times are negatively correlated? Here’s a hint: First think about what the scatterplot of arrival times would look like with a positive (or negative) correlation.
To make this more concrete, let’s go back to assuming that each person’s arrival time follows a normal distribution with mean 30 minutes (after noon) and standard deviation 10 minutes. Now let’s assume that the arrival times of Michael and LeBron have a correlation coefficient of 0.7. Later we’ll change the correlation coefficient to -0.7. Once again, let’s approach this problem with intuition, then simulation, and then mathematics.
Intuition: A positive correlation between Michael’s and LeBron’s arrival times means that one is more likely to arrive early when the other arrives early, and one is more likely to arrive late when the other arrives late. Therefore, we expect less variability in the distribution of differences, and we expect the probability of successfully meeting to increase with a positive correlation. On the other hand, a negative correlation means that one is more likely to arrive late when the other arrives early, and vice versa. With a negative correlation, we expect a smaller probability of successfully meeting.
Simulation: Below is some R code for simulating arrival times from a bivariate normal distribution. Below that are some results for 10,000 repetitions, with the positive correlation on the left and negative correlation on the right:
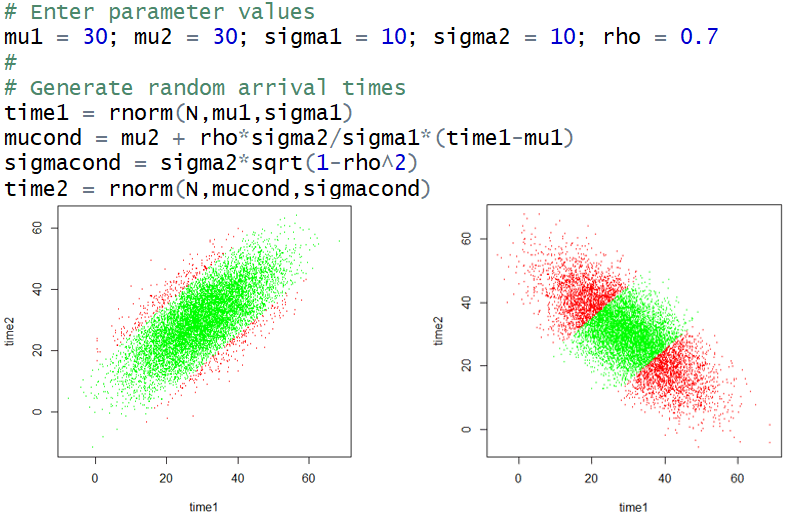
We see from the graph on the left that a positive correlation makes Michael and LeBron more likely to arrive at similar times, which increases their probability of successfully meeting (approximately 0.9486 from these 10,000 repetitions). Similarly, we see from the graph on the right that a negative correlation makes Michael and LeBron much less likely to successfully meet (approximately 0.5859 from these 10,000 repetitions).
Mathematics: We know that the difference in arrival times (X – Y) follows a normal distribution with mean 30 – 30 = 0, as when the arrival times were independent. The non-zero correlation changes the standard deviation of (X – Y), as shown in the following histograms of simulated differences in arrival times:
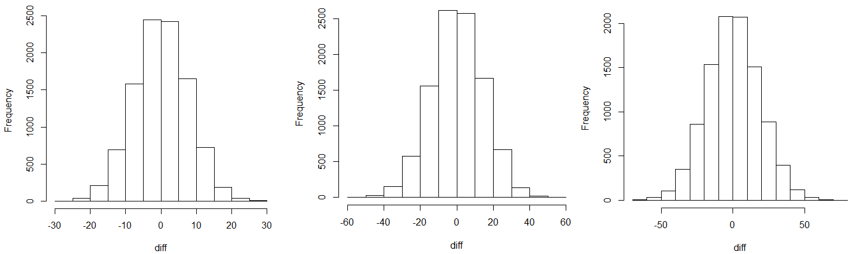
You might ask students: Which graph do you think goes with which value of the correlation coefficient (0, 0.7, -0.7)? The answer is that the positive correlation produced the graph on the left, negative correlation for the one on the right, and zero correlation for the middle graph. Why does this make sense? As mentioned above, a positive correlation in arrival times produces less variability in differences, and a negative correlation produces more variability in differences.
Now let’s proceed to calculations, which go well beyond the scope of most introductory statistics courses. The difference (X – Y) still follows a normal distribution with mean 0, but the standard deviation is different from the case of independent arrival times. The key result is:
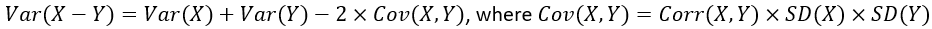
With a correlation coefficient of 0.7, this produces Cov(X, Y) = 0.7×10×10 = 70 and Var(X – Y) = 10^2 + 10^2 -2(70) = 60, so SD(X – Y) = sqrt(60) ≈ 7.746 minutes. As expected, this is a smaller SD than in the case of independent (correlation zero) arrival times. We can then calculate Pr(-15 < (X – Y) < 15) ≈ 0.9472 (with z-scores ≈ ±1.94). As expected, this probability is larger than before. Note that this is quite close to the approximate probability from the simulation results, which is reassuring to see after such an involved calculation.
For the case of an equally strong but negative correlation between the two arrival times, we obtain SD(X – Y) = sqrt(340) ≈ 18.439, which is much larger than before. This leads to Pr(-15 < (X – Y) < 15) ≈ 0.5841 (with z-scores ≈ ±0.81), which is a considerably smaller probability than before, quite consistent with the approximation from simulation.
These calculations are summarized in the table:

This extension of the “random rendezvous” probability problem replaces uniform with normal distributions for the arrival times. This change gives students a chance to practice calculations related to normal distributions and also to apply properties of random variables. This extension also allows students to develop their intuition and to perform more simulation analyses. Changing the means and/or standard deviations of arrival times offers more questions that require intuition, simulation, and mathematics. Allowing the arrival times to be positively or negatively correlated adds another dimension to this problem, which can be tackled with intuition and simulation even if the mathematics might be beyond typical students of introductory statistics.
We could analyze even more extensions of this problem, such as using probability distributions other than uniform or normal. The simulation analysis would involve minimal changes to the code we’ve already written. The mathematical analysis would require calculating double integrals to determine the volume under a joint probability density function over the region in which the two people meet.
Oh, but look at the time! I’m running late for a lunch engagement and would hate to miss meeting my friend, so I really must be going …


That’s perfect that the answer to a question about Michael and LeBron came out to 23.
LikeLike
Great point, Steve. Also, it’s clearly poor planning on my part that this was post #24 rather than post #23.
LikeLike