#37 What’s in a name?
Delivered by Juliet on her iconic balcony, Shakespeare’s poetic what’s in a name speech is one of the most famous in the English language.
What does this have to do with teaching introductory statistics? Well, there’s a lot of data that one could collect on students’ names. An obvious but boring example is to count the number of letters in a name. A more fun, albeit silly, option is to determine the number of Scrabble points in a name. I often collected these data from students early in my teaching career.
I have abandoned this practice in recent years, primarily because I want students to analyze more important and consequential datasets. But I am starting to rethink this for two reasons. First, there’s nothing wrong with occasionally using a dataset that’s silly and fun. Second, this dataset is rich with potential for achieving pedagogical goals, such as exploring the seemingly simple but actually challenging concept of a statistical tendency.
I mentioned in post #35 (Statistics of illumination, part 4, here) that psychologist Keith Stanovich has called probabilistic reasoning “the Achilles heel of human cognition.” Data on Scrabble points in students’ names can help students to confront misunderstandings about this topic. The research question to be investigated is: Do people with longer names have more Scrabble points? The answer is yes, as long as we are careful to regard this as a statistical tendency and not a hard-and-fast rule. What does this mean? We’ll explore that question in this post. As always, questions for posing to students appear in italics.
Here are the Scrabble point values of the 26 letters:

Just to make sure that we’re all clear: Shakespeare has 11 letters and 20 Scrabble points (1 + 4 + 1 + 5 + 1 + 1 + 3 + 1 + 1 + 1 + 1 = 20) in his name. Juliet has 6 letters and 13 points, and Romeo has 5 letters and 7 points*. Among these three names, a name with more letters than another always has more Scrabble points. So far this is a rule and not just a tendency. But one need not look far to find an exception to this rule: Romeo’s friend Mercutio has 8 letters but only 12 points, so his name has more letters but fewer points than Juliet’s.
* This website (here) is helpful for speeding up these calculations.
Because longer names do tend to produce more points than shorter names, I propose examining the ratio of a name’s points to letters as a measure of the name’s Scrabble-strength. These ratios are approximately 1.818 for Shakespeare, 2.167 for Juliet, 1.400 for Romeo, and 1.500 for Mercutio. By this measure, Juliet has the Scrabble-strongest name and Romeo the least.
For the purpose of this post, I will use the names of the fifty states in the U.S. to illustrate the kinds of questions that can be asked and analyses that can be performed. Before I show you the data: Make a guess for the state with the most letters, the state with the most points, and the state with the largest ratio. Are your guesses made? Ready for the answers? Here’s the list of states, along with region of the country, number of words in the name, number of letters, number of Scrabble points, and ratio of points to letters:
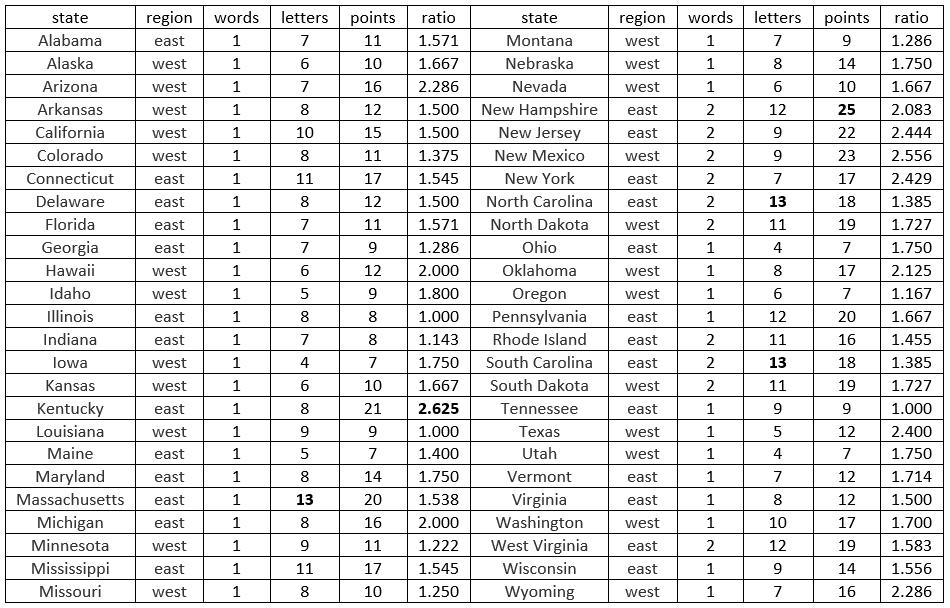
Which states win bragging rights? As indicated in bold in the table, Massachusetts, North Carolina, and South Carolina tie for the most letters with 13. New Hampshire takes first place in number of Scrabble points with 25. In the most coveted ratio category, the winner is Kentucky with 2.625 points per letter.
Now let’s return to the original question: Do states with more letters tend to have more points? But first we can ask students a more basic question: What kind of graph would you produce to investigate this question? Because both variables are numerical, we can examine a scatterplot of points versus letters:
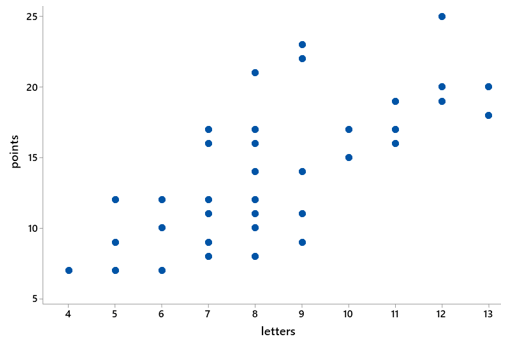
Does this graph reveal a tendency for states with more letters to have more points? How can you tell? Yes, this graph displays a positive association between points and letters. For example, states with 10 or more letters all have 15 or more points, whereas states with 6 or fewer letters all have 12 or fewer points.
What statistic could we calculate to quantify this tendency? Make an educated guess for its value with these data. Again because these are both numerical variables, we can calculate the correlation coefficient between points and letters. Its value turns out to be 0.735, indicating a fairly strong, positive association.
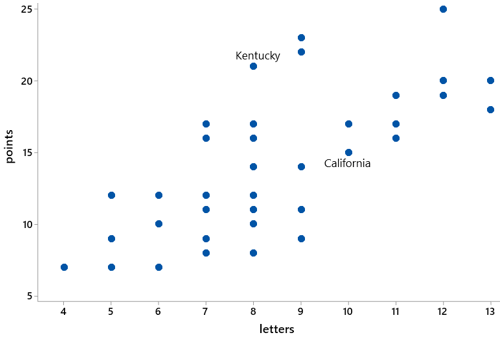
Can you identify a pair of states for which the state with more letters has fewer points? Indicate one such pair of states on the graph. Many pairs of states buck the overall trend in this way. One example is that Kentucky has fewer letters (8 vs. 9) but more points (21 vs. 15) than California, as shown here:
Another way to think about a statistical tendency is: Suppose that we select two of the fifty states at random. Make an educated guess for the probability that the state with more letters also has more points. This is equivalent to asking: Among all pairs of states, in what percentage does the state with more letters also have more points? There are 50×49/2 = 1225 pairs of states. I wrote a small program in R to analyze these 1225 pairs. It turns out that 161 of the pairs have the same number of letters or the same number of points. Of the remaining 1064 pairs, 802 satisfy the overall tendency (the state with more letters also has more points), and 262 run counter to that tendency. So, the probabilities for a randomly selected pair of states are 802/1225 ≈ 0.655 that the state with more letters also has more points, 262/1225 ≈ 0.214 that the state with more letters has fewer points, and 161/1225 ≈ 0.131 that the states have the same number of letters or points. If we restrict our attention to the pairs of states without ties, the probability is 802/1064 ≈ 0.754 that the state with more letters also has more points. To simplify: The overall probability is about two-thirds that the state with more letters has more points, and this increases to three-fourths if we eliminate ties.
The following graph displays the least squares regression line for predicting number of points from number of letters:
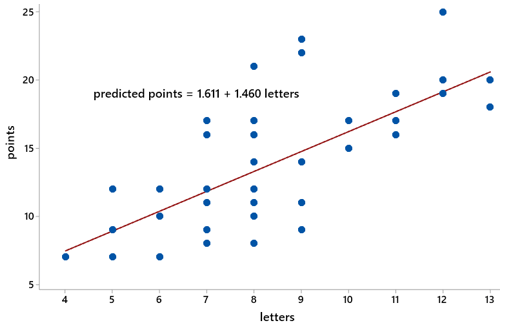
How many points would this line predict for Puerto Rico, if it were to become a state? Puerto Rico has 10 letters, so the line would predict 1.611 + 1.460 × 10 = 16.211 points. Assess the accuracy of this prediction. Puerto Rico actually has 14 Scrabble points, so the prediction overestimates by 2.211 points, which is an overestimate of about 15.8%. Repeat for Guam. Guam has 4 letters, so the line would predict 1.611 + 1.460 × 4 = 7.451 points, compared to 7 actual points for Guam. This is an overestimate of only 0.451 points, for a percentage error of just 6.4%.
We can also use these data to look for a statistical tendency in comparing two groups. Do you expect that states with two words in their name will tend to have more Scrabble points than states with one-word names?
Before we investigate this question, here’s a more basic one: What kind of graph can we use to answer these questions? Most students recognize that this question involves comparing two groups on a numerical response, so we can use comparative dotplots or boxplots. Consider these graphs:
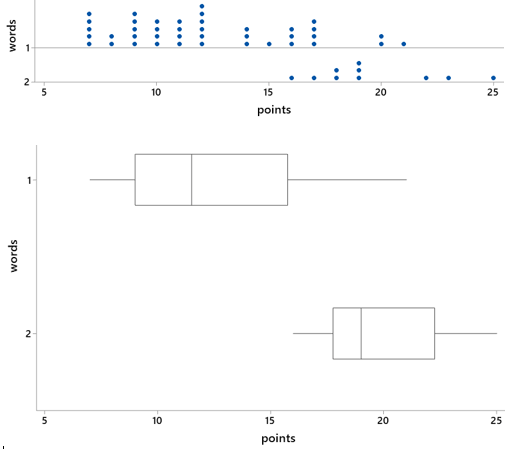
Do these graphs reveal that two-word states tend to have more points than one-word states? Yes, absolutely. From the boxplots, we see that every value in the five-number summary of points is higher for the two-word states than the one-word states. In particular, the median number of points is 19 for the two-word states, 11.5 for the one-word states. The dotplots also reveal that every two-word state has at least 16 points, but only 10 of 40 one-word states have 16 or more points.
Can you identify a pair of states that do not satisfy the overall tendency? Certainly, there are many such pairs. The most extreme example is that (one-word) Kentucky has 21 points and (two-word) Rhode Island has 16 points. I wrote some R code to analyze the 40×10 = 400 pairs of states (with a one-word and a two-word state) and found that 305 follow the overall tendency (meaning that the two-word state has more points than the one-word state), 68 run counter to the tendency, and 27 have a tie for number of points.
Could we incorporate information on number of words in the state’s name into the scatterplot of points versus letters? If so, how? What do you expect to see? Yes, here is a coded scatterplot, with one-word states represented by blue circles and two-word states by red squares:
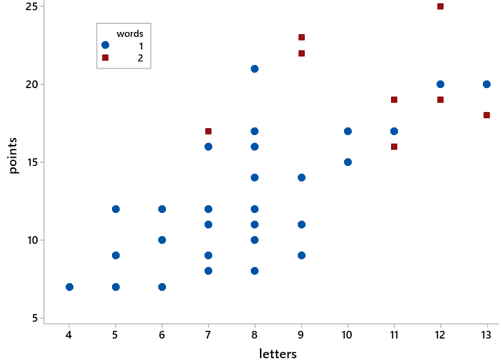
What does this graph reveal? As expected, the two-word states appear in the top right part of the graph, indicating that they tend to have more letters and more points than one-word states. Also, perhaps surprisingly, the association between points and letters is much weaker among the two-word states than the one-word states.
Now let’s bring the ratio (points to letters) variable into the analysis. Which group – one-word states or two-word states – do you expect to have larger ratio values, on average? Do you expect the difference between the groups to be substantial or small? Ready to see the graphs? Here you go:
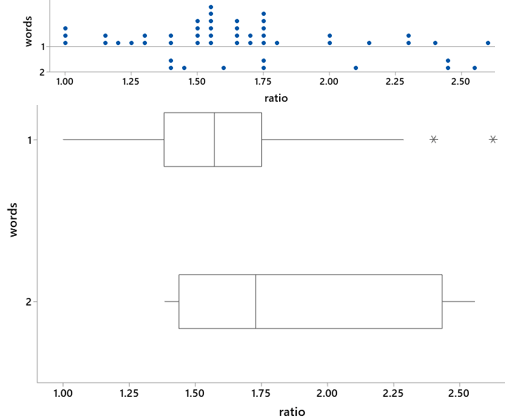
Compare and contrast the distributions of ratio values between these groups. The two-word states have slightly larger ratios, on average, than one-word states. The medians are approximately 1.73 and 1.57 for the two-word and one-word states, respectively. The two-word states also have more variability in ratio values than one-word states. Both distributions appear to be slightly skewed to the right, more so for the two-word states. The one-word states have two outliers on the high end of the ratio values – Kentucky (2.625 points per letter) and Texas (2.400 points per letter).
Now: What kind of relationship (if any) do you expect to see in a scatterplot of ratio versus letters? How about in a scatterplot of ratio versus points? Ready to find out? Here are the graphs:
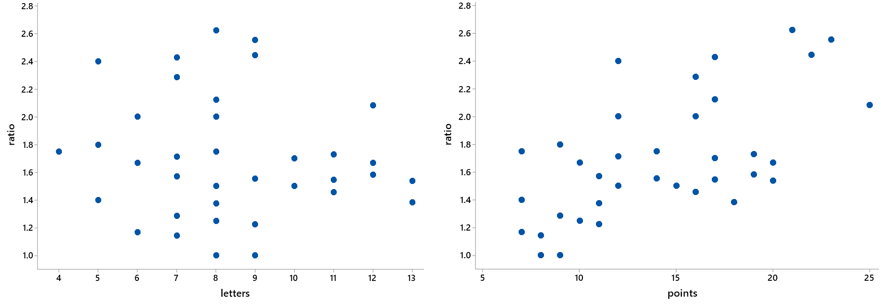
Describe what these graphs reveal. Also make educated guesses for the values of the two correlation coefficients. As expected, we see that the ratio is positively associated with number of points. But the association is slightly negative with number of letters. It turns out that correlation coefficients are 0.554 between ratio and points, -0.142 between ratio and letters.
Which variable – points or letters – would be more helpful for predicting ratio? Determine the equation of this least squares line. Also calculate and interpret the value of r-squared. Number of points will clearly be more helpful for predicting ratio than number of letters. The equation of the least squares line turns out to be: predicted ratio = 1.034 + 0.04674 × points. The value of r-squared is 30.7%, indicating that 30.7% of the variability in states’ ratios is explained by knowing their number of points. This value is perhaps surprisingly small, considering that number of points is used directly in the calculation of ratio.
Do you think the regression model would be substantially improved by adding number of letters, as well as number of points, to the predictors of ratio? Some students think that the answer is clearly yes, because number of letters is included in the calculation of ratio, just as number of points is included. Other students believe that the answer is clearly no, because the scatterplot reveals a very weak association (correlation -0.142) between ratio and letters. Software tells us that the regression model with both predictors is: predicted ratio = 1.6723 + 0.12095 × points – 0.20029 × letters. It makes sense that the coefficient is positive for number of points and negative for number of letters. The value of r-squared for this regression model is 96.4%, dramatically greater than the value of 30.7% based only on number of points as a single predictor. The two predictors together do much better at predicting a state’s ratio value than the sum of their usefulness as individual predictors.
Some students might ask themselves: Hold on, we can calculate a state’s ratio exactly from its number of points and number of letters, so why is r-squared not 100%? The answer is that multiple regression incorporates variables in the model additively, whereas the calculation of ratio involves dividing points by letters.
Can we find a clever work-around that uses multiple regression to predict ratio from points and letters exactly, with an r-squared value of 100%? Yes, we can. The key is to transform all three variables by taking logarithms. Here are scatterplots of the transformed data:
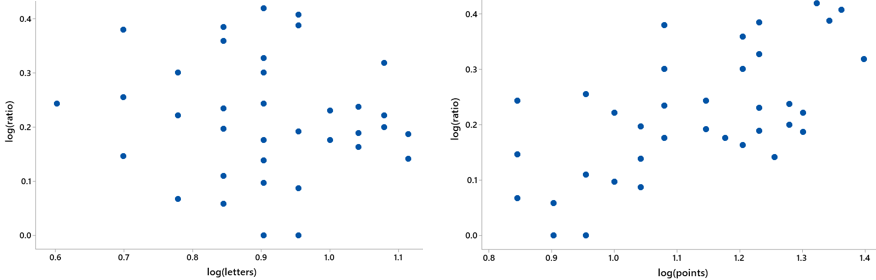
What do these graphs reveal? We see a moderate positive association between log(ratio) and log(points), and there’s very little association between log(ratio) and log(letters). These graphs provide no hint of what the multiple regression model will reveal.
The multiple regression model with these transformed variables turns out to be: log(ratio) = log(points) – log(letters). The value of r-squared with this model is 100%! What happens when you back-transform this equation to get rid of the logs*? The right-hand side of the equation can be expressed as: log(points/letters). Then exponentiating both sides of the equation produces what we knew it would: ratio = points/letters.
* How about that: a chance to work with properties of logarithms!
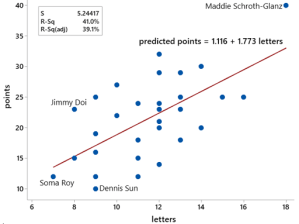
Asking your students to analyze data from their own names is more fun than analyzing states’ names. Let me show you some results from data on my colleagues rather than students. The following graph comes from data on the 33 faculty members listed on the faculty directory webpage (here) for the Statistics Department at Cal Poly – San Luis Obispo in the Winter quarter of 2020:
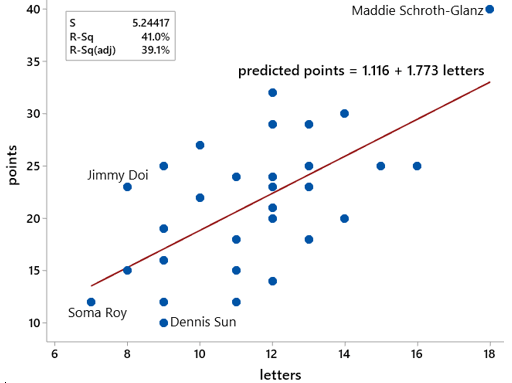
The graph reveals who wins bragging rights: Maddie Schroth-Glanz has the most letters (18) and Scrabble points (40) in her name, while Jimmy Doi has the largest ratio of points to letters (23/8 = 2.875 points per letter)*. The smallest values were proudly achieved by Soma Roy for the fewest letters (7) and Dennis Sun for the fewest points (10) and smallest ratio (1.111)**.
* I used names as they appeared on the faculty directory webpage. I realize that using James instead of Jimmy, or Madeleine instead of Maddie, would have changed the data.
** Where is my name? I have slightly more letters than average (12, average 11.4) but many fewer points than average (14, average 21.4). Needless to say, this makes my points-to-letters ratio one of the smallest among my colleagues (1.167, third smallest of 33 names).
Again we see a statistical tendency here, as names with more letters tend to have more points. But a longer name does not guarantee more points, which is what makes this a tendency rather than a rule. Among the 33×32/2 = 528 pairs of names, 327 follow the tendency and 127 run counter to it, with 74 ties.
The regression line for predicting points from letters is also given in the graph, along with the r-squared value of 41.0%. The line is a bit steeper than with the states’ names (slope 1.773 points per letter for faculty, compared to 1.460 points per letter for the states). The value of r-squared is smaller for the faculty than for the states: 41.0% versus 54.1%.
Analyzing people’s names provides an opportunity to analyze paired data. The following graph displays Scrabble points of last names versus first names for these faculty, along with a 45 degree line:
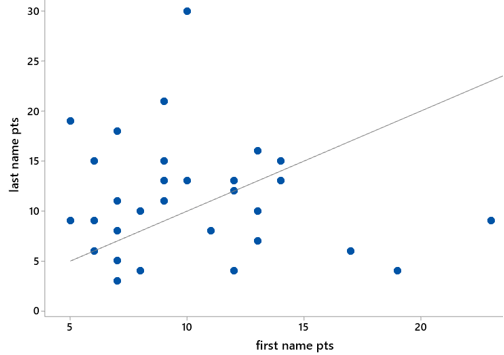
What tendency is revealed by most of the names falling above the 45 degree line? A slight tendency for more points in a faculty member’s last name than first name.
Depending on your course goals and student audience, you could also ask students to do some coding associated with data on Scrabble points. Such an activity could include scraping names from a webpage, and it might also use a mapping of letters-to-points for games other than Scrabble, such as Words with Friends. I recently attended an inspiring presentation by Paul Myers (9 letters, 16 points, 1.778 ratio), who asks high school students in a data science* class to write code (in both Excel and R) for calculating numbers of letters and Scrabble points in names.
* Have you noticed that data science has more letters, more Scrabble points, and a larger points-to-letters ratio than statistics?
Recommendation #3 of the GAISE report (here) is: Integrate real data with a context and purpose. These data on Scrabble points do not have much purpose, other than being fun, but they do provide opportunities to explore statistical concepts. Chief among these is the concept of a statistical tendency, which is quite fundamental but can prove elusive to many students.
Perhaps if Shakespeare had been a (far-ahead-of-his-time) statistician or data scientist, he might have asked: What tends to be in a name?
P.S. An Excel file with the data on states’ names can be found below. Graphs in this post were produced with Minitab statistical software.
P.P.S. As so many teachers prepare to teach remotely in the coming weeks, I regret that I have no experience with online teaching and so have no advice to offer*. Because I am on leave this academic year, I am not embarking on this foray into a brave new world alongside so many of you. I wish you and your students well in these challenging circumstances.
* Other than: Ask good questions! 🙂
P.P.P.S. I’m a big fan of simulations*. I highly recommend this article (here) by Harry Stevens, which shows simulations of virus spread under four conditions, illustrating the potential impact of social distancing.
* See posts #12, #13, and #27 (here, here, and here) on simulation-based inference, post #14 (here) on interpreting confidence level, and posts #23 and #24 (here and here) for simulation analyses of a probability problem.


Trackbacks & Pingbacks