#68 Knowing or guessing?
I told my students at the beginning of our last class session that I was especially excited about class that day for several reasons:
- It was a Friday.
- We were about to work through our thirteenth handout of the term, a lucky number.
- The date was October 16, the median day for the month of October.
- We had reached the end of week 5 of our 10-week quarter, the halfway point.
- The topic for the day was my favorite probability rule, in fact my favorite mathematical theorem: Bayes’ rule.
The first two examples that we worked through concerned twitter use and HIV testing, as described in post #10, My favorite theorem, here.
The third and final example of the day presented this scenario: Suppose that Jasmine* has a 70%** chance of knowing (with absolute certainty) the answer to a randomly selected question on a multiple-choice exam. When she does not know the answer, she guesses randomly among the five options.
* I had always used the name Brad with this made-up example. But I realized that I had used an example earlier in the week with the names Allan, Beth, Chuck, Donna, and Ellen, so I thought that I should introduce a bit of diversity into the names of fictional people in my made-up probability examples. I did a google search for “popular African-American names” and selected Jasmine from the list that appeared.
** When I first rewrote this example with Jasmine in place of Brad, my first thought was to make Jasmine a stronger student than Brad, so I wrote that she has an 80% rather than a 70% chance of knowing the answer for sure. Later I realized that this change meant that the value 20% was being used for the probability of her guessing and also for the probability of her answering correctly given that she is guessing. I wanted to avoid this potential confusion, so I changed back to a 70% chance of Jasmine knowing the answer.
a) Before we determine the solution, make a prediction for the probability that Jasmine answers a randomly selected question correctly. In other words, make a guess for the long-run proportion of questions that she would answer correctly.
I hope students realize that this probability should be a bit larger than 0.7. I want them to reason that she’s going to answer 70% correctly based on her certain knowledge, and she’s also going to answer some correctly when she’s guessing just from blind luck. I certainly do not expect students to guess the right answer, but it’s not inconceivable that some could reason that she’ll answer correctly on 20% of the 30% that she guesses on, which is another 6% in addition to the 70% that she knows for sure, so her overall probability of answering correctly is 0.76.
Next I ask students to solve this with a table of counts for a hypothetical population, just as we did for the previous two examples (again see post #10, here). This time I only provide them with the outline of the table rather than giving row and column labels. b) Fill in the row and column labels for the table below:
To figure out what labels to put on the rows and columns, I remind students that the observational units here are 100 multiple choice questions, and they need to think about the two variables that we record about each question. It takes most students a little while to realize that the two variables are: 1) whether Jasmine knows the answer or guesses, and 2) whether Jasmine answers the question correctly or not. This leads to:
c) Fill in the table of counts for a hypothetical population of 100 questions. We proceed through the following calculations:
- Jasmine will know the answer for 70% of the 100 questions, which is 70.
- She will guess at the answer for 100 – 70 = 30 questions.
- For the 70 questions where she knows the answer, she will correctly answer all 70, leaving 0 that she will answer incorrectly.
- For the 30 questions on which she guesses, we expect her to answer correctly on one-fifth of them, which is 6.
- That leaves 30 – 6 = 24 questions for which she will guess and answer incorrectly.
- The column totals are therefore 76 correctly answered questions and 24 incorrect.
The completed table is shown here:
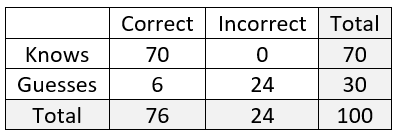
d) Use the table to report the probability that Jasmine answers a randomly selected question correctly. This can read from the table to be: Pr(correct) = 76/100 = 0.76.
e) Show how this unconditional probability (of answering a randomly selected question correctly) can be calculated directly as a weighted average of two conditional probabilities. This is more challenging for students, but I think the idea of weighted average is an important one. I want them to realize that the two conditional probabilities are: Pr(correct | know) = 1.0 and Pr(correct | guess) = 0.2. The weights attached to these are the probabilities of knowing and of guessing in the first place: Pr(know) = 0.7 and Pr(guess) = 0.3. The unconditional probability of answering correctly can be expressed as the weighted average 0.7×1.0 + 0.3×0.2 = 0.76.
f) Determine the conditional probability, given that Jasmine answers a question correctly, that she actually knows the answer. Some students think at first that this conditional probability should equal one, but they realize their error when they are asked whether it’s possible to answer correctly even when guessing. Returning to the table, this conditional probability is calculated to be: 70/76 ≈ 0.921.
g) Interpret this conditional probability in a sentence. Jasmine actually knows the answer to about 92.1% of all questions that she answers correctly in the long run.
h) Show how to calculate this conditional probability directly from Bayes’ rule. The calculation is: Pr(know | correct) = [Pr(correct | know) × Pr(know)] / [Pr(correct | know) × Pr(know) + Pr(correct | guess) × Pr(guess)] = (1×0.7) / (1×0.7 + 0.2×0.3) = 0.70 / 0.76 ≈ 0.921. I try to impress upon students that even though this calculation looks more daunting with the formula than from filling in the table, the calculations are exactly the same, as seen by our ending up with 0.70/0.76 from the formula and 70/76 from the table. I also emphasize that I think the table provides an effective and understandable way to organize the calculations.
Here’s a fun extension of this example: Continue to suppose that Jasmine has a 70% chance of knowing (with absolute certainty) the answer to a randomly selected question on a multiple-choice exam. But now there’s also a 20% chance that she can eliminate three incorrect options, and then she guesses randomly between the remaining two options, one of which is correct. For the remaining 10% chance, she has no clue and so guesses randomly among all five options.
i) Before conducting the analysis, do you expect the probability that she answers a question correctly to increase, decrease, or remain the same? Explain. Then do the same for the conditional probability that she knows the answer given that she answers correctly.
Most students have correct intuition for the first of these questions: If Jasmine can eliminate some incorrect options, then her probability of answering correctly must increase. The second question is more challenging to think through: Now that she has a better chance of guessing the correct answer, the conditional probability that she knows the answer, given that she answer correctly, decreases.
j) Modify the table of hypothetical counts to determine these two probabilities. Students must first realize that the table now needs three rows to account for Jasmine’s three levels of knowledge. The completed table becomes:
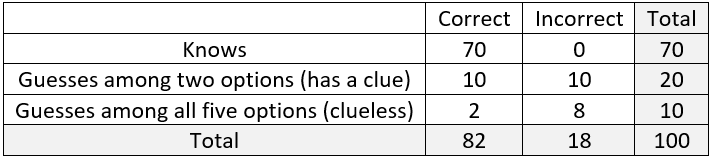
The requested probabilities are: Pr(correct) = 82/100 = 0.82 and Pr(know | correct) = 70/82 ≈ 0.854. Jasmine’s ability to eliminate some incorrect options has increased her probability of answering correctly by six percentage points from 76% to 82%. But our degree of belief that she genuinely knew the answer, given that she answered correctly, has decreased by a bit more than six percentage points, from 92.1% to 85.4%.
I confess that I did not have time to ask students to work through this extension during Friday’s class. I may give it as an assignment, or as a practice question for the next exam, or perhaps as a question on the next exam itself.
I have mentioned before that I give lots and lots of quizzes in my courses (see posts #25 and 26, here and here). This is even more true in my first-ever online course. I generally assign three handout quizzes and three application quizzes per week. The handout quiz aims to motivate students to work through the handout, either by attending a live zoom session with me, or on their own, or by watching a video that I prepare for each handout. The application quiz asks students to apply some of the topics from the handout to a new situation. I also occasionally assign miscellaneous quizzes. With regard to Bayes’ rule, I have asked my students to watch a video (here) that presents the idea behind Bayes’ rule in an intuitive and visually appealing way. I wrote a miscellaneous quiz to motivate students to watch and learn from this video.
The author of this video, Grant Sanderson, argues that the main idea behind Bayes’ rule is that “evidence should not determine beliefs but update them.” I think the Jasmine example of knowing versus guessing can help students to appreciate this viewpoint. We start with a prior probability that Jasmine knows the answer to a question, and then we update that belief based on the evidence that she answers a question correctly. Do I know with absolute certainty that this example helps students to understand Bayes’ rule? Of course not, but I like the example anyway. More to the point, the evidence of my students’ reactions and performances on assessments has not persuaded me to update my belief in a pessimistic direction.

