#39 Batch testing
One of my favorite examples for studying discrete random variables and expected values involves batch testing for a disease. I would not call this a classic probability problem, but it’s a fairly common problem that appears in many probability courses and textbooks. I did not intend to write a blog post about this, but I recently read (here) that the Nebraska Public Health Lab has implemented this idea for coronavirus testing. I hope this topic is timely and relevant, as so many teachers meet with their students remotely in these extraordinary circumstances. As always, questions that I pose to students appear in italics.
Here are the background and assumptions: The idea of batch testing is that specimens from a group of people are pooled together into one batch, which then undergoes one test. If none of the people has the disease, then the batch test result will be negative, and no further tests are required. But if at least one person has the disease, then the batch test result will be positive, and then each person must be tested individually. Let the random variable X represent the total number of tests that are conducted. Let’s start with a disease probability of p = 0.1 and a sample size of n = 8. Assume that whether or not a person has the disease is independent from person to person.
a) What are the possible values of X? When students need a hint, I say that there are only two possible values. If they need more of a hint, I ask about what happens if nobody in the sample has the disease, and what happens if at least one person in the sample has the disease. If nobody has the disease, then the process ends after that 1 test. But if at least one person has the disease, then all 8 people need to undergo individual tests. The possible values of X are therefore 1 and 9.
b) Determine the probability that only one test is needed. For students who do not know where to start, I ask: What must be true in order that only one test is needed? They should recognize that only one test is needed when nobody has the disease. Because we’re assuming independence, we calculate the probability that nobody has the disease by multiplying each person’s probability of not having the disease. Each person has probability 0.9 of not having the disease, so the probability that nobody has the disease is (0.9)^8 ≈ 0.430.
c) Determine the probability for the other possible value of X. Because there are only two possible values, we can simply subtract the other probability from 1, giving 1 – (0.9)^8 ≈ 0.570. I point out to students that this is the probability that at least one person in the sample has the disease. I also note that it’s often simplest to calculate such a probability with the complement rule: Pr(at least one) = 1 – Pr(none).
d) Interpret these probabilities with sentences that begin “There’s about a _____ % chance that __________ .” I like to give students practice with expressing probabilities in sentence form: There’s about a 43% chance that only one test is needed, and about a 57% chance that nine tests are needed.
e) Display the probability distribution of X in a table. For a discrete random variable, a probability distribution consists of its possible values and their probabilities. We can display this probability distribution as follows:
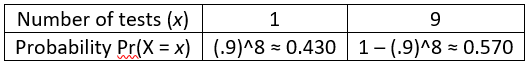
f) Determine the expected value of the number of tests that will be conducted. With only two possible values, this is a very straightforward calculation: E(X) = 1×[(.9)^8] + 9×[1–(.9)^8] = 9 – 8×[(.9)^8] ≈ 5.556 tests.
g) Interpret what this expected value means. In post #18 (What do you expect, here), I argued that we should adopt the term long-run average in place of expected value. The interpretation is that if we were to repeat this batch testing process for a large number of repetitions, the long-run average number of tests that we would need would be very close to 5.556 tests.
h) Which is more likely – that the batch procedure will require one test or nine tests? This is meant to be an easy one: It’s more likely, by a 57% to 43% margin, that the procedure will require nine tests.
i) In what sense is batch testing better than simply testing each individual at the outset? This is the key question, isn’t it? Part (h) suggests that perhaps batch testing is not helpful, because in any one situation you’re more likely to need more tests with batch testing than you would with individual testing from the outset. But I point students who need a hint back to part (g): In the long run, you’ll only need an average of 5.562 tests with batch testing, which is fewer than the 8 tests you would always need with individual testing. If you need to test a large number of people, and if tests are expensive or in limited supply, then batch testing provides some savings on the number of tests needed.
The questions above used particular values for the number of people (n) and the probability that an individual has the disease (p). Next I ask students to repeat their analysis for the general case.
j) Specify the probability distribution of X, in terms of n and p. If students need a hint, I remind them that there are still only two possible values of X. If nobody has the disease, only 1 test is needed. If at least one person has the disease, then (n+1) tests are needed. The probability that only 1 test is needed is the product of each individual’s probability of not having the disease: (1–p)^n. Then the complement rule establishes that the probability of needing (n+1) tests is: 1–(1–p)^n. The probability distribution of X is shown in the table:
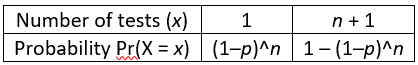
k) Determine the expected value of the number of tests, as a function of n and p. The algebra gets a bit messy, but setting this up is straightforward: E(X) = 1×[(1–p)^n] + (n+1)×[1–(1-p)^n], which simplifies to n+1–n×[(1–p)^n].
l) Verify that this function produces the expected value that you calculated above when n = 8 and p = 0.1. I want students to develop the habit of mind to check their work like this on their own, but I can model this practice by asking this question explicitly. Sure enough, plugging in n = 8 and p = 0.1 produces E(X) = 5.556 tests.
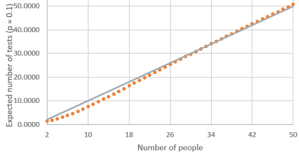
m) Graph E(X) as a function of n, for values from 2 to 50, with a fixed value of p = 0.1. Students can use whatever software they like to produce this graph, including Excel:
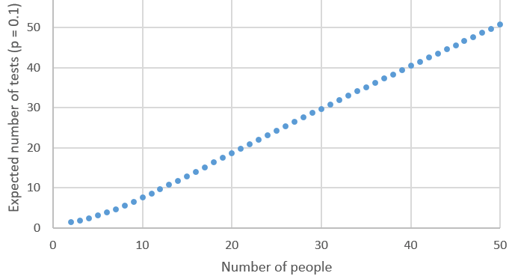
n) Describe the behavior of this function. This is an increasing function. This makes sense because having more people produces a greater chance that at least one person has the disease, so this increases the expected number of tests. The behavior of the function is most interesting with a small sample size. The function is slightly concave up for sample sizes less than 10, and then close to linear for larger sample sizes.
o) Determine the values of n for which batch testing is advantageous compared to individual testing, in terms of producing a smaller expected value for the number of tests. Here’s the key question again. We are looking in the graph for values of n (number of people) for which the expected number of tests (represented by the dots) is less than the value of n. The gray 45-degree line in the following graph makes this comparison easier to see:
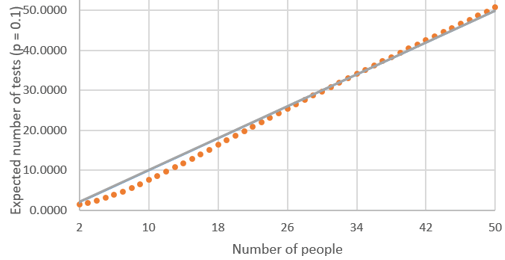
From this graph, we see that the expected number of tests with 25 people is a bit less than 25, and the expected number of tests with 35 people is slightly greater than 35, but it’s hard to tell from the graph with 30 people. We can zoom in on some values to see where the expected number of tests begins to exceed the sample size:
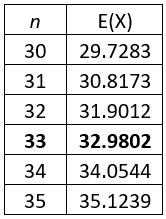
This zoomed-in table reveals that the expected number of tests is smaller with batch testing, as compared to individual testing, when there are 33 or fewer people. (Remember that we have assumed that the disease probability is p = 0.1 here.)
p) Now graph E(X) as a function of p, for values from 0.01 to 0.50 in multiples of 0.01, with a fixed value of n = 8. Here is what Excel produces:
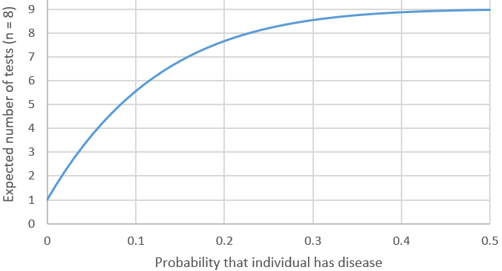
q) Describe the behavior of this function. This function is also increasing, indicating that we expect to need more tests as the probability of an individual having the disease increases. The rate of increase diminishes gradually as the probability increases, approaching a limit of 9 tests.
r) Determine the values of p for which batch testing is advantageous compared to individual testing. Looking at the graph, we see that the expected number of tests is less than 8 for values of p less than 0.2. We also see that the exact cutoff value is a bit larger than 0.2, but we need to perform some algebra to solve the inequality:
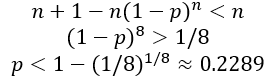
s) Express your finding from the previous question in a sentence. I ask this question because I worry that students become so immersed with calculations and derivations that they lose sight of the big picture. I hope they’ll say something like: With a sample size of 8 people, the expected number of tests with batch testing is less than for individual testing whenever the probability that an individual has the disease is less than approximately 0.2289.
Here’s a quiz question that I like to ask following this example, to assess whether students understood the main idea: The following table shows the expected value of the number of tests with batch testing, for several values of n and p:
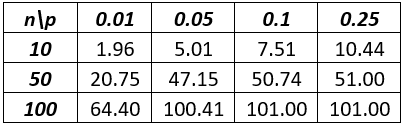
a) Show how the value 47.15 was calculated. b) Circle all values in the table for which batch testing is advantageous compared to individual testing.
Students should answer (a) by plugging n = 50 and p = 0.05 into the expected value formula that we derived earlier: 50 + 1 – 50×[(1–0.05)^50] ≈ 47.15. To answer part (b), students should circle the values in bold below, because the expected number of tests is less than n, the number of people who need testing:
Here is an extension of this example that I like to use on assignments and exams: Suppose that 8 people to be tested are randomly split into two groups of 4 people each. Within each group of 4 people, specimens are combined into a single batch to be tested. If anyone in the batch has the disease, then the batch test will be positive, and those 4 people will need to be tested individually. Assume that each person has probability 0.1 of having the disease, independently from person to person. a) Determine the probability distribution of Y, the total number of tests needed. b) Calculate and interpret E(Y). c) Is this procedure better than batch-testing all 8 people in this case? Justify your answer.
Some students struggle with the most basic step here, recognizing that the possible values for the total number of tests are 2, 6, and 10. The total number of tests will be just 2 if nobody has the disease. If one batch has nobody with the disease and the other batch has at least one person with the disease, then 4 additional tests are needed, making a total of 6 tests. If both batches have at least one person with the disease, then 8 additional tests are needed, which produces a total of 10 tests.
The easiest probability to calculate is the best-case scenario Pr(Y = 2), because this requires that none of the 8 people have the disease: (.9)^8 ≈ 0.430. Now students do not have the luxury of simply subtracting this from one, so they must calculate at least one of the other probabilities. Let’s calculate the worst-case scenario Pr(Y = 10) next, which means that at least one person in each batch has the disease: (1–.9^4)×(1–.9^4) ≈ 0.118.
At this point students can determine the remaining probability by subtracting the sum of the other two probabilities from one: Pr(Y = 6) = 1 – Pr(Y = 2) – Pr(Y = 10) ≈ 0.452. For students who adopt the good habit of solving such problems in multiple ways as a check on their calculations, they could also calculate Pr(Y = 6) as: 2×(.9^4)×(1–.9^4). It’s easy to forget the 2 here, which is necessary because either of the two batches could be the one with the disease.
The following table summarizes these calculations to display the probability distribution of Y:
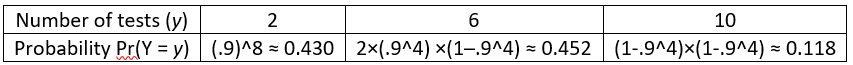
The expected value turns out to be: E(Y) = 2×0.430 + 6×0.452 + 8×0.118 ≈ 4.751 tests*. If we were to repeat this testing procedure a large number of times, then the long-run average number of tests needed would be very close to 4.751. This is smaller than the expected value of 5.556 tests when all eight specimens are batched together. This two-batch strategy is better than the one-batch plan, and also better than simply conducting individual tests. In the long run, the average number of tests is smallest with the two-batch plan.
* An alternative method for calculating this expected value is to double the expected number of tests with 4 people from our earlier derivation: 2×[4+1–4×(.9^4)] ≈ 4.751 tests.
This is a fairly challenging exam question, so I give generous partial credit. For example, I make part (a) worth 6 points, and students earn 3 points for correctly stating the three possible values. They earn 1 point for any one correct probability, and they also earn a point if their probabilities sum to one. Part (b) is worth 2 points. Students can earn full credit on part (b) by showing how to calculate an expected value correctly, even if their part (a) is incorrect. An exception is that I deduct a point if their expected value is beyond what I consider reasonable in this context. Part (c) is also worth 2 points, and students can again earn full credit regardless of whether their answer to part (b) is correct, by comparing their expected value to 5.556 and making the appropriate decision.
As I conclude this post, let me emphasize that I am not qualified to address how practical (or impractical) batch testing might be in our current situation with coronavirus. My point here is that students can learn that probabilistic thinking can sometimes produce effective strategies for overcoming problems. More specifically, the batch testing example can help students to deepen their understanding of probability rules, discrete random variables, and expected values.
This example also provides an opportunity to discuss timely and complex issues about testing for a disease when tests are scarce or expensive. One issue is the difficulty of estimating the value of p, the probability than an individual to be tested has the disease. In the rapidly evolving case of coronavirus, this probability varies considerably by place, time, and health status of the people to be tested. Here are some data about estimating the probability that an individual to be tested has the disease:
- The COVID Tracking Project (here) reports that as of March 29, the United States has seen 139,061 positive results in 831,351 coronavirus tests, for a percentage of 16.7%. The vast majority who have taken a test thus far have displayed symptoms or been in contact with others who have tested positive, so this should not be regarded as an estimate of the prevalence of the disease in the general public. State-by-state data can be found here.
- Also as of the afternoon of March 29, the San Luis Obispo County (where I live) Public Health Department has tested 404 people and obtained 33 positive results (8.2%). Another 38 positive test results in SLO County have been reported by private labs, but no public information has been released about the number of tests conducted by these private labs. Information for SLO is updated daily here.
- Iceland has conducted tests much more broadly than most countries, including individuals who do not have symptoms (see here). As of March 29, Iceland’s Directorate of Health is reporting (here) that 1020 of 15,484 people (6.6%) have tested positive for coronavirus.
Also note that the assumption of independence in the batch testing example is unreasonable if the people to be tested have been in contact with each other. In the early days of this pandemic, one criterion for being tested has been proximity to others who have tested positive. Another note is that the batch testing analysis does not take into account that test results may not always be correct.
Like everyone, I hope that more and more tests for coronavirus become widely available in the very near future.
P.S. For statistics teachers who are making an abrupt transition to teaching remotely, I recommend the StatTLC (Statistics Teaching and Learning Corner) blog (here), which has recently published several posts with helpful advice on this very timely topic.


Trackbacks & Pingbacks