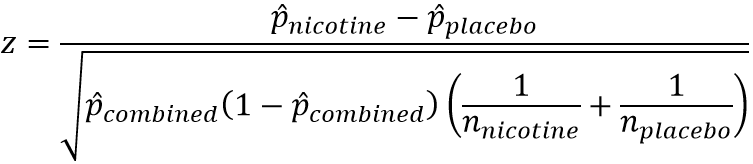#84 Giving oral exams
This guest post has been contributed by Paul Roback and Kelly McConville. Paul and Kelly both teach statistics at top-notch liberal arts college – St. Olaf College for Paul and Reed College for Kelly. In fact, Kelly was a student of Paul’s at St. Olaf. Paul and Kelly are both exceptional teachers who are making substantial contributions to statistics and data science education. I am very pleased that they agreed to write a guest blog post about their experiences with giving oral exams to their students while teaching online in the fall term. You can contact them at roback@stolaf.edu and mcconville@reed.edu.
What was your motivation for giving oral exams/quizzes?
Paul: For years I’ve had the conversation with other statistics teachers that “you can often tell within a few minutes of talking with a student how well they understand the material.” In these conversations, we’ve often fantasized about administering oral exams to get a more accurate read on students in a shorter amount of time. But when assessment time came, I always retreated to the tried-and-true written exam, usually in-person but sometimes take-home. This fall, since I was teaching fully online due to the pandemic and things were already pretty different, I decided to take the plunge to oral exams, both to see how effective they could be, and to build in an opportunity for one-on-one connections with my (virtual) students. Of course, when I say “take the plunge,” you’ll see it’s more like getting wet up to my knees in the shallow end rather than a cannonball off the high dive into the deep end, but it was a start!
Kelly: Teaching online gave me the push I needed to really rethink my forms of assessment, especially my exams. In the past, I would give in-person exams that were mostly short-answer questions with a strong focus on conceptual understanding and on drawing conclusions from real data*.
* If you are looking for good conceptual questions, they are all over Allan’s blog, such as post #21 (here). I have borrowed many a question from Allan!
I didn’t feel that these exams would translate well to a take home structure, partly because now students could just read Allan’s blog to find the correct answers! I also figured an assessment shake-up would help me fix some of the weaknesses of my in-person exams. For example, I struggled to assess a student’s ability to determine which methods to use. I didn’t give them access to a computer and so I had to do most of the analysis heavy-lifting and then leave them to explain my work and draw sound conclusions.
Another strong motivator was the one-on-one interaction component of the oral exam. During my in-person class, I make an effort to learn all students’ names by the start of Week 2, and I try to interact with every student regularly. I struggled to translate these practices to the online environment, so I appreciated that the oral exam allowed the lab instructors and me to check-in and engage with each student.
In which course did you use an oral exam, and at what stage?
Kelly: This fall I was teaching introductory statistics and for the first time ever, I was teaching it online. Across the two sections, my two lab instructors and I had a total of 74 students. We administered two exams, each of which included two parts: a two-hour, open-book, open-notes, take-home exam followed by a ten-minute oral exam. During the take-home part, students were presented with a dataset and asked questions that required them to draw insights from the data. This part required them to complete all their computations in R and document their work using R Markdown. The oral exam built from the data context on the take-home and focused more on their conceptual understanding of relevant statistical ideas.
Paul: I used an oral quiz in our Statistical Modeling course. This course has an intro stats prerequisite, and it mostly covers multiple linear and logistic regression. In addition to the usual assessments from weekly homework, exams, and a project, I added two “mini-tests” this semester, each worth 10% of the total grade. The first allowed me to give extensive feedback to early written interpretations of modeling results; the second was an oral quiz following students’ first assignment (available here) on logistic regression.
Describe your oral quiz/exam in more detail.
Paul: Students had weekly written homework assignments due on Friday, and then they signed up for 15-minute slots on the following Monday or Tuesday to talk through the assignment. I posted an answer key over the weekend, in addition to oral quiz guidelines (here) that we had discussed in class. With the mini-test, I wanted students to (a) talk through their homework assignment, (b) make connections to larger concepts, and (c) apply newfound knowledge and understanding to new but similar questions. Students could start by selecting any problem they wanted from their homework assignment and walk me through their approach and answer. They were encouraged to “try to add some nuance and insight that goes beyond the basic answer in the key.” Next, I would ask about other questions in the homework assignment, focusing on concepts and connections more than ultra-specific responses. For example, from the sample questions I listed in the oral quiz guidelines, I asked students to describe, “What is the idea behind a drop-in-deviance test?” or “Why do we create a table of empirical logits for a numeric predictor?” Finally, if students seemed to have a good handle on the assignment they completed, I would show them output from the same dataset but with a different explanatory variable, and then ask them to interpret a logistic regression coefficient or suggest and interpret exploratory plots. Not all students made it to the final stage, which was just fine, but it also capped their possible score.
Kelly: For the midterm exam, the students analyzed data related to the Flint water crisis (here). The oral exam questions asked about identifying the type of study, interpreting coefficients in a linear model they built for the take-home component, and drawing conclusions from the “How blood lead levels changed in Flint’s children” graph in the FiveThirtyEight article by Anna Maria Barry-Jester (here).
For the final exam, the students explored the police stops data presented in the Significance article “Racial disparities in police stops in US cities” by Roberto Rivera and Janet Rossenbaum. The original data can be grabbed from the Stanford Open Policing Project (here), and wrangled data can be found in their github repository (here). My exam focused on traffic stops in June of 2016 in San Francisco. For the take-home component, students explored the relationship between a driver’s race and whether or not they were searched. Then, the oral component focused on assessing students’ conceptual understanding of key statistical inference ideas. This included interpreting a p-value in their own words, grappling with types of errors, and explaining how the accuracy and precision of a confidence interval are affected as the sample size or confidence level are increased.
How did you address student anxiety about oral exams?
Kelly: Even though I only had ten precious minutes with each student, I used two of those minutes to combat student unease. At the beginning of the oral exam, I talked through what to expect and reassured students that: a) brief pauses to consider the question were completely allowed, and b) they could think out loud and I would take the answer they ended on, not where they began. I spent the last minute of the exam (if we still had time) with light-hearted pleasantries. Throughout the exam, I was very mindful to maintain a cheerful expression and to nod (regardless of the quality of their answer) so that they felt comfortable and like I was “cheering them on.”
Paul: If I think about my undergraduate self taking an oral exam in statistics, I would have been a sweaty, stammering mess, at least in the first few minutes. Therefore, I wanted to try to create an atmosphere that was as “un-intimidating” as possible. I actually did two things along these lines: a) ask students to reflect on their recent course registration experience, which everyone had a strong opinion on because we had a rocky debut of a new system, and b) let each student pick any problem to start with, where I asked them to talk me through their thought process and share insights instead of just quoting an answer. Letting them choose their own problem to start with worked really well. Most thought carefully about which one to choose and were clearly prepared. I think this gave them confidence right off the bat. For those who hadn’t prepared, well, that was usually a sign of things to come.
How did you assess student responses?
Paul: I created a scoring rubric based on one used by Allison Theobold at Cal Poly:
- 4 = Outstanding ability to articulate and connect logistic regression concepts, with comprehensive and thoughtful understanding of topics.
- 3 = Good ability to articulate and connect logistic regression concepts, with clear understanding of most topics.
- 2 = Limited ability to articulate and connect logistic regression concepts, with an understanding of some big ideas but also some misconceptions.
- 1 = Little to no ability to articulate and connect logistic regression concepts, with a limited understanding of big ideas and many misconceptions.
- 0 = Wait, have we talked about logistic regression??
I assigned scores in half-steps from 4.5 down to 2.0. Because we were on zoom, I recorded every discussion (with student permission), just in case I needed to go back and review my assigned score. As it turns out, I didn’t go back and review a single conversation! I was able to assign a score to each student immediately after our conversation. I received no complaints from students and did not second-guess myself.
Kelly: The lab instructors and I did all the 10-minute oral exams via Zoom over the course of two days. I recorded my sessions (with student permission), in case I wanted to review them afterward, though I didn’t end up needing to. During the oral exam, I typed terse notes. While likely indecipherable to anyone else, these were enough for me to be able to go back and fill in later. I didn’t want my notetaking to get in the way of our statistical conversation or to cause additional anxiety for the student.
Between sets of 6-9 oral exams, I gave myself 30-minute breaks to fill in my feedback on Gradescope, assign a score, and take a breather so that I could start the next set with a high level of engagement. (I didn’t want any of the students to realize I felt like Bill Murray’s character did when he experienced Groundhog Day for the 27th time.)
My assessment rubric was pretty simple and reflected the accuracy and completeness of the student’s answer for each question. As I stated earlier, I gave each student feedback on the components they got wrong, along with encouraging feedback about what they got right. I definitely didn’t give points for eloquence. Overall, the oral exam represented about 25% of each student’s exam grade.
What would you do differently in the future, and what aspects would you maintain?
Kelly: In the future, I will consider having a question bank instead of asking each student the same set of questions. I like to think there wasn’t much cheating on the oral exams, but a student definitely could have shared the questions they were asked with a friend who took the exam at a later time. I will also increase the testing slots to 15 minutes to allow for a bit more in-depth discussion of a concept.
I think I need to develop a clearer idea upfront of how much the instructors should lead students who are missing the mark. I firmly believe that learning can happen during an exam, and an instructor’s leading questions can help a student who has strayed off the path to get back on and connect ideas. For consistency, the lab instructors and I did very little leading this first time around. When a student didn’t have much of an answer to a question, we just moved on to the next question. I think that led to some missed learning opportunities.
In terms of what I’ll keep, I liked that the exam built off a data context that the students had already explored, so we didn’t have to spend time setting up the problem. I will also continue asking questions that require explanations, requiring them to verbalize their thought process.
Paul: Although I plan to keep learning from others’ experiences and from researchers who have systematically studied oral exams, aspect that I’d like to keep include:
- Basing the exam on a recently completed assignment. To me, this provided a good base from which to launch into discussions of concepts and connections.
- Allowing students to choose ahead of time the first question they’ll answer. More than one student admitted how nervous they were when we were just starting, but they seemed to calm down after successfully going through their prepared response. Several admitted at the end that the oral exam went much faster and was not nearly as scary as they feared.
- Having an adaptive and loose script. I believe I was able to fairly evaluate students even without a fixed set of questions (and there’s no risk that fixed script can get out), and the conversation felt more genuine, authentic, and personal, adapted to a student’s level of understanding.
- Conducting it over zoom. Even though this is less personal than meeting in person, it’s great for sharing screens back and forth, for maintaining a tight timeline and extending into evening hours, and for recording the conversation.
- Keeping the length at 15 minutes. Anything less seems too rushed and not conversational enough, but anything more seems unnecessary for establishing a proper assessment.
- Grading with the 4-point rubric. I’m convinced that the total time spent developing, administering, and grading the exam was significantly less than with a conventional written test, and the grades were just as reflective of students’ learning.
Aspects that I’d likely change up include:
- I would not include the “non-stats” ice-breaker question. I think a little friendly chit-chat, followed by an initial question that the student has prepared, suffices to alleviate a lot of oral-exam anxiety.
- I might stretch 44 15-minute exams over three days instead of just two days, but I felt pretty energized throughout, and I preferred to bite the bullet and keep things to a short timeframe.
- Give students a chance to practice talking aloud through their thought processes beforehand, not just for an oral exam in my class, but for future technical interviews.
- Keep thinking about effective questions. For example, I could give students data with a context and ask them to talk me through an analysis, from EDA to ultimate conclusions.
- I really didn’t provide students with much feedback other than comments during the exam and their final score. I would love to find a way to provide a little more feedback, but I would not want to sacrifice being fully present during the conversation.
Did the oral exam/quiz meet your aspirations? Once you return to face-to-face classes, will you continue to give oral exams/quizzes?
Paul: Yes! This spring my challenge is to adapt this idea to courses in Statistical Theory, where I’ve always wanted to do oral exams, and Intro to Data Science, where I haven’t previously imagined oral exams).
Kelly: I really feel like I was better able to assess a student’s comprehension of statistical concepts with the oral exam than I have been with my in-class exams. On a paper exam, you often just see the final answer, not the potentially winding road that got the student there and, for incorrect answers, where faulty logic seeped into the student’s thought process.
However, at the same time, I didn’t get to ask nearly as many conceptual questions this way. I could see using both types of exams when I am back to the in-person classroom, which I am looking forward to!