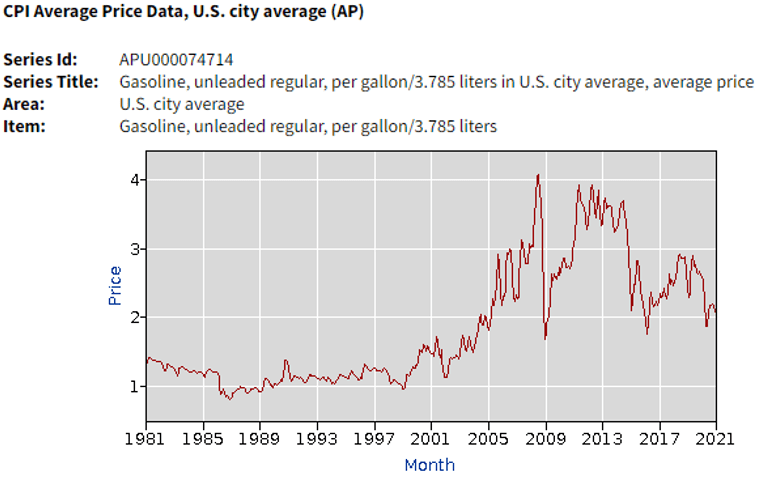
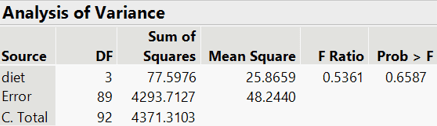
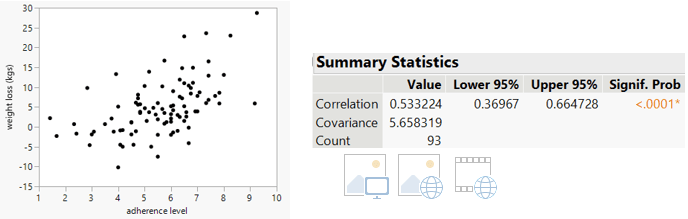
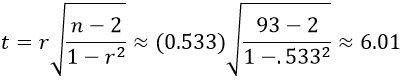#94 Non-random words
I am teaching a course called Statistical Communication during this spring quarter*. This course aspires to help Statistics majors, most of whom are completing their second year, to improve their written communication skills with regard to statistical ideas and analyses. These students have taken at least two statistics courses, and most have taken several more than that. This class meets synchronously but remotely, with a total of fifty students across two sections. I am teaching this course for the first time and have never taught a similar course.
* Cal Poly is on the quarter system, so we teach three ten-week (plus finals week) terms per year, not including summer. Now that we have reached the second half of April, we are three weeks into the Spring term. We only have one week between quarters, during which we must finish grading for Winter term and then get ready for the Spring term. Because that’s not much time to prepare for a new course that is very different from any I’ve taught before, I warned my students on day one that I’ll be winging it, figuring out what happens in each class session as we go along.
This post describes a recent class session for this course. As always, questions that I posed to students appear in italics.
The handout that I prepared for the class meeting bore the same title as this post: Non-random words. I introduced students to the topic as follows:
One of the challenges in communicating well about statistics and data is that many terms that describe statistical concepts also have meanings in common, everyday conversation. For some terms, the statistical and everyday meanings match up very well, so the common use can help with understanding the statistical meaning. But for other terms, the everyday meaning is different enough to provide a hindrance to understanding the statistical meaning.
a) Join a breakout room, and prepare a list of statistical terms that also have common, everyday meanings. Also think about the statistical and everyday meanings. Then try to classify each term with regard to how closely the everyday meaning matches the statistical meaning.
I gave students about 12 minutes for this discussion, with 4-5 students in each breakout room. Before I opened the breakout rooms, I provided an example by pointing to the title of the handout. I suggested that random is a prime example of a word for which its meanings in everyday conversation are not completely aligned with statistical uses of the word.
b) We will reconvene as a full class to compile this list and discuss how closely the meanings align.
Some words that my students suggested include: normal, uniform, mean, range, distribution, correlation, significant, confident, independent, risk, odds, chance, effect, control, interaction, block, confounding, sample, population, parameter, factor, response, model, residual, error.
Before class, I had generated my own list. After giving my students about ten minutes to suggest their words, I looked at my list and found several that had not been mentioned yet: bias, expected, variance, association, statistic, tendency, likelihood, skew.
Next I asked students which words are the most problematic, in that the everyday usage hinders understanding of the statistical meaning. Some words that students put in this category include: normal, odds, independent, significant, power, control, block.
Our discussion of questions (a) and (b) took more than half of the 50-minute class session. For the rest of the time, I turned our discussion to an in-depth discussion of the word random:
c) On a scale of 0 – 10, how important would you say the word “random” is in statistics?
I asked students to respond to this question in the zoom chat window*. All of their responses were on the high side, ranging from 7 to 10, with a majority at 9 or 10.
* I wish that I had thought ahead to prepare this as a zoom poll question. I think almost all students would have responded to a poll question, whereas only about ten students in each section responded in the chat.
d) What do you think “random” means in everyday (or even slang) usage?
Some common responses were to say surprising, unusual, and unlikely. Other synonyms offered were odd and weird. Slightly longer responses included out-of-the-ordinary and out-of-context. For example, if someone says that a “random” thing happened to them today, they probably mean that it was an unusual, out-of-the-ordinary, occurrence.
A second type of response referred to being haphazard or unpredictable, lacking a pattern or plan.
e) Look up some definitions of “random” in an online dictionary.
I wanted my students to think first for themselves about everyday meanings of “random.” But then I figured that I should take advantage of knowing that the students are all online during class. Some dictionary definitions that they provided include:
- Unknown, unspecified
- Without method or conscious decision
- Lacking definite purpose or plan
f) In what ways is “random” used in statistics?
I intended to spend a good bit of time on this question. Because most students take this course about halfway through their undergraduate career, it provides a good opportunity to review some of the most important topics that they should have learned. Prior to the class meeting, I had four aspects of “random” in mind for this discussion:
- Random sampling aims to select a representative sample from a population, so findings about the sample can be generalized to the population.
- Random assignment tends to produce similar treatment groups, to enable cause-and-effect conclusions if the treatment groups reveal a significant difference in the response.
- Random selection applies to situations such as choosing a representative from a group of people or dealing out cards in a game.
- Random variables can model various real-world phenomena, such as waiting time at a fast-food restaurant or number of transactions at an automatic teller machine.
I don’t think I’m very good at leading class discussions, in part because I often have a specific endpoint in mind as I did with this question. Sometimes I even confess to my students that I’d like them to read my mind, even though I know that’s completely unfair to ask. In this case my students read my mind quite well and suggested a variation on each of these four aspects of the word “random.”
g) Would you say that the everyday usage of “random” is a help or a hindrance when trying to communicate statistical uses of the word?
Once again, I wish that I had prepared this as a poll question in advance. Instead I asked students to reply in the chat window, and most of them were reluctant to do that. Those who volunteered an answer voted for hindrance, which is the response I was hoping for.
I proposed to students that there is substantial irony here. In everyday usage random means having no method or plan. But random sampling and random assignment are very specific methods that require a lot of planning to implement. Similarly, a random variable provides a very specific, predictable pattern for the long-run behavior of what it’s modeling, even though the outcome of a specific instance is unpredictable.
I try to think a lot about what kind of assessments to provide after a class session like this. In this case, I made two small assignments and am contemplating a third, more substantial one.
I’ve mentioned many times that I give lots of quizzes in my courses. Following this class session, I gave my students a very easy quiz. I simply asked them to select their five favorite words that illustrate the distinction between everyday and statistical meanings. I realize that this quiz amounted to giving free points for showing up to class, paying a modest amount of attention, and taking a few minutes to respond in Canvas. But I hope students gave a little reflection as they answered, and I enjoyed reading their responses to see which words most resonated with them.
I also created a discussion in Canvas in which I asked students: Describe an example that uses a word with a specific statistical meaning in a way that carries a different meaning than the statistical one. I’m thinking of the words that we discussed and listed in connection with the “Non-random Words” handout. Be very clear about which word(s) you are referring to. Also describe what you perceive to be the intended meaning of the word(s). If you found the example online, include a link. I kicked off this discussion with an example that had appeared in my inbox just that morning: I received an email message inviting me to attend a webinar titled “A Conversation on Power, Structural Racism, and Perceptions of Normality in STEM Through a Lens of Critical Race Theory.” The statistical words used in non-statistical ways are power and normality. In this context, power refers to authority or control over others, and normality refers to what is typical or expected. Here is a link to the webinar announcement.
I am also considering asking students to write an essay with these instructions: Select one of the words that we identified in class. Write an essay of 250-400 words in which you describe how the statistical meaning of the word compares to the everyday meaning. Mention similarities as well as differences, if there are similarities. Provide at least one example to explain the word’s meaning in statistics. Write as if to a relative of yours who is well-educated and intellectually curious but has not specialized in a STEM field and has never taken a statistics course. Be sure to cite any references that you use (e.g., dictionary, textbook, wikipedia, …)
I have not given this assignment yet, because I am trying to balance students’ workload (and my grading load) with other assignments. I am also debating whether I should ask them to select from a small list of words that I provide, such as: normal, bias, error, power, independent, expectation.
I realize that few readers of this blog are teaching a course called Statistical Communication. I suspect that you might be thinking: What does this have to do with teaching introductory statistics*?
* Even though I italicized this question for emphasis, this one is directed at myself and perhaps you, rather than students.
Many words have slightly or substantially different meanings in statistics than in everyday conversation, which can present a hurdle for introductory students to overcome. I think we can help students by highlighting such discrepancies, as with the word random. By pointing out that such words have a particular meaning in statistics that differs from what students might expect*, we can help them to concentrate on the statistical meanings that we’d like them to learn. Also, even though few courses have the word “communication” in their title, many introductory courses have an explicit or implicit learning objective to help students learn to communicate effectively with data.
* By all means, do not expect the statistical meaning of the word expect to mean what your students might expect. See post #18, titled What do you expect?, here.