#4 Statistics of illumination, part 2
This is the second post in my “Statistics of illumination” series, in which I present examples to illustrate that statistics can shed light on important questions. I use these examples on the first day of a statistical literacy course and also in presentations to high school students. The methods used are quite simple, but the ideas involved are fairly sophisticated. Click here for the first post in this series. Questions that I pose to students appear in italics below.
This example is based on a consulting project undertaken by my friend Tom Short, which he and his collaborators described in a JSE article (here). The research question is whether cancer pamphlets are written at the appropriate level to be understood by cancer patients. The data collection involved two aspects. A sample of cancer patients were given a reading test, and a sample of cancer pamphlets were analyzed for their readability. The data for both patients and pamphlets are on the same grade level scale; for example, 8 means that a patient could read at the 8th grade level, or that a pamphlet’s readability was at the 8th grade level. The data are summarized in the following two tables:

How might you go about measuring these characteristics: reading level of patients and readability of pamphlets?
Your students have probably taken lots of reading tests, but the idea of measuring readability of text might be new to them. Measuring readability can involve aspects such as the average length of a sentence, average length of a word, and rate of polysyllabic words.*
* I often joke that my favorite polysyllabic word is “polysyllabic.” That one word has more syllables than my entire teaching philosophy: Ask good questions.
Explain why it’s not possible to calculate the mean reading level of a patient, based on how the data are presented here.
Most students correctly note that this is not possible because we need numerical values to calculate a mean, so the “below 3” and “above 12” categories prevent that.
Is it possible to calculate the median reading level of a patient?
Many students correctly respond that this is indeed possible, because we simply need ordered data to determine the middle value. The non-numeric categories are on the two extremes and not in the middle, so they do not impede calculating the median.
Calculate the median reading level of a patient and the median readability level of a pamphlet.
For the patients, students need to determine the (63+1)/2 = 32nd value in order. This gives some students pause, until they realize that they need to add up the counts for each grade level until they reach the 32nd value. I point out that they can count from the top or bottom; that’s the whole point that the median is in the middle! Because there are an even number of pamphlets (30), students need to calculate the average of the 15th and 16th values in order. The median values turn out to be grade level 9 for both the patients’ reading levels and the pamphlets’ readability levels.
Now we arrive at the key question:
Does the two medians being the same indicate that the patients’ reading levels and the pamphlets’ readability levels are well matched up with each other?
Many students have an initial reaction of yes. I suppose I’m guilty of leading them to think this by asking them to calculate the medians before getting to this question. For these students, I offer a substantial hint to point in a helpful direction:
What proportion of patients have a reading level below that of the simplest pamphlet?
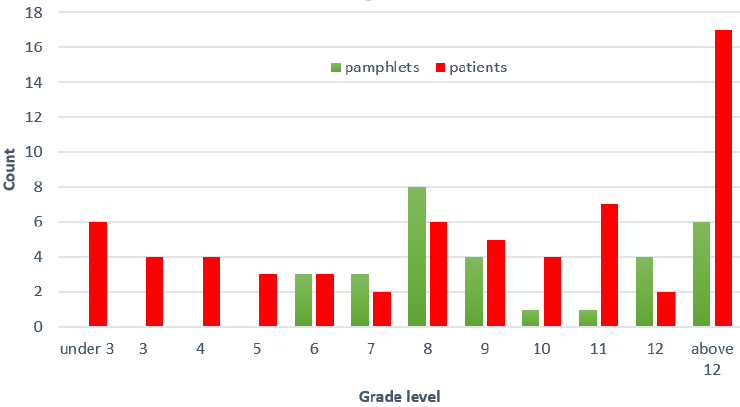
The answer is 17/63 ≈ .270. This means that 27% of the patients have a reading level below that of the simplest pamphlet. This is clearly a problem, indicating that the patients’ reading levels and pamphlets’ readability levels are not well aligned. Granted, it might not be possible to present cancer pamphlet information below sixth grade readability, but something has to be done to help the 27% of patients who cannot read at the sixth grade level or higher.
As I argued with the first example in this series, I think this small example illustrates statistical thinking. More specifically, I emphasize four take-home messages for students from this example:
1. Start with a graph. In this activity I purposefully led students into a bad habit: calculating summary statistics (medians, in this case) without first making a graph to look at the data. The graph below clearly shows that the patients and pamphlets are not well aligned, because there’s a lot of red (representing patients) and no green (representing pamphlets) at the bottom of the scale. In other words, the left side of the graph makes clear that many patients do not have a pamphlet that they can read.
2. Think about variability. The discipline of statistics is all about variability, which is an obvious but easy to overlook fact of life. Not everyone is the same: different people read at different levels. Not all pamphlets are the same: some are easier to read than others. Whereas measures of center, such as mean and median, are often very helpful, they tell us nothing about variability.
3. Think in terms of distribution. It’s easy for us instructors to under-estimate how hard this is for students. It’s much easier for students to see 63 reading levels, but understanding the distribution of those 63 values as a single entity, rather than as 63 separate things, is a very challenging cognitive step for many students. Why is this so important here? The question of whether pamphlets are well-aligned to patients is about how well the two distributions (of patients’ reading levels, of pamphlets’ readability levels) match up with each other across all reading levels.
4. Address the research question in context. I sometimes use this example as a very open-ended question on a final exam, if I have not presented it earlier in the course. Some students try to apply a two-sample t-test to these data. I suspect this is because they think it’s somehow better to use more sophisticated methods rather than simpler ones. But even if a two-sample t-test could be performed here (it can’t because the sample mean reading level of the patients cannot be calculated), such a test would not address the motivating question, just like calculating medians above did nothing to address the question. Always make sure that your analysis of data addresses the reason that the data were collected.
P.S. I mentioned at the outset that Tom Short introduced me to these data, early in his career when he was teaching at Villanova University. Tom and I became friends in graduate school. From there we embarked on careers focused on teaching statistics. He and I frequently attended conferences and workshops together, and we collaborated on several education projects. I learned a lot about both statistics and teaching from Tom, often through conversations that we had while walking in places as varied as the streets of San Francisco and the beaches of Daytona. We also enjoyed talking about sports and competing in a fantasy baseball league, in which Tom managed the wonderfully-named Markov Fielders. Tom died unexpectedly in November of 2018, a great loss to the many friends, colleagues, and students who were enriched by knowing him. On Wednesday of this week I will be chairing a memorial session for Tom at the Joint Statistical Meetings. I dedicate this blog post to him.


Trackbacks & Pingbacks