#61 Text as data

This guest post has been contributed by Dennis Sun. You can contact him at dsun09@calpoly.edu.
Dennis Sun is a colleague of mine in the Statistics Department at Cal Poly. He teaches courses in our undergraduate program in data science* as well as statistics. Dennis also works part-time as a data scientist for Google. Dennis is a terrific and creative teacher with many thought-provoking ideas. I am very glad that he agreed to write this guest post about one aspect of his introductory course in data science that distinguishes it from most introductory courses in statistics.
* My other department colleague who has taught for our data science program is Hunter Glanz, who has teamed with Jo Hardin and Nick Horton to write a blog about teaching data science (here).
I teach an “Introduction to Data Science” class at Cal Poly for statistics and computer science majors. Students in my class are typically sophomores who have at least one statistics course and one computer science course under their belt. In other words, my students arrive in my class with some idea of what statistics can do and the programming chops to execute those ideas. However, many of them have never written code to analyze data. My course tries to bring these two strands of their education together.
Of course, many statisticians write code to analyze data. What makes data science different? In my opinion, one of the most important aspects is the variety of data. Most statistics textbooks start by assuming that the data is already in tabular form, where each row is an observation and each column is a variable. However, data in the real world comes in all shapes and sizes. For example, an audio file of someone speaking is data. So is a photograph or the text of a book. These types of data are not in the ready-made tabular form that is often assumed in statistics textbooks. In my experience, there is too much overhead involved to teach students how to work with audio or image data in an introductory course, so most of my non-standard data examples come from the world of textual data.
I like to surprise students with my first example of textual data: Dr. Seuss books. Observations in this “dataset” include:
- “I am Sam. I am Sam. Sam I am….”
- “One fish, two fish, red fish, blue fish….”
- “Every Who down in Whoville liked Christmas a lot….”
and so on. To analyze this data using techniques they learned in statistics class, it first must be converted into tabular form. But how?
One simple approach is a bag of words. In the bag of words representation, each row is a book (or, more generally, a “document”), and each column is a word (or, more generally, a “term”). Each entry in the table is a frequency representing the number of times a term appears in a document. This table, called the “term-frequency matrix,” is illustrated below:

The resulting table is very wide, with many more columns than rows and most entries equal to 0. Can we use this representation of the data to figure out which documents are most similar? This sparks a class discussion about how and why a data scientist would do this.
How might we quantify how similar two documents are? Students usually first propose calculating some variation of Euclidean distance. If xi represents the vector of counts in document i, then the Euclidean distance between two documents i and j is defined as:
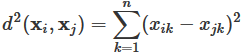
This is just the formula for the distance between two points that students learn in their algebra class (and is essentially the Pythagorean theorem), but the formula is intimidating to some students, so I try to explain what is going on using pictures. If we think of xi and xj as vectors, then d(xi, xj) measures the distance between the tips of the arrows.
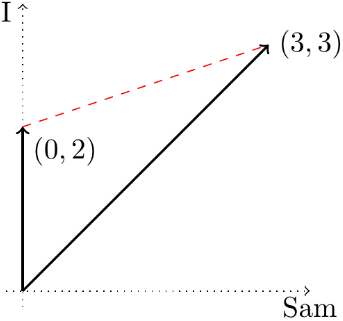
For example, suppose that the two documents are:
- “I am Sam. I am Sam. Sam I am.”
- “Why do I like to hop, hop, hop? I do not know. Go ask your Pop.”
and the words of interest are “Sam” and “I.” Then the two vectors are x1 = (3,3) and x2 = (0,2), because the first document contains 3 of each word, and the second includes no “Sam”s and two “I”s. These two vectors, and the distance between them, are shown here:
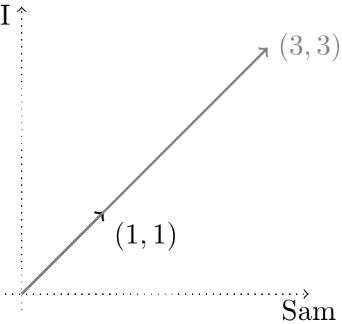
At this point, a student will usually observe that the frequencies scale in proportion to the length of the document. For example, the following documents are qualitatively similar:
- “I am Sam.”
- “I am Sam. I am Sam. Sam I am.”
yet their vectors are not particularly close, since one vector is three times the length of the other:
How could we fix this problem? There are several ways. Some students propose making the vectors the same length before comparing them, while others suggest measuring the angles between the vectors. What I like about this discussion is that students are essentially invoking ideas from linear algebra without realizing it or using any of the jargon. In fact, many of my students have not taken linear algebra yet at this point in their education. It is helpful for them to see vectors, norms, and dot products in a concrete application, where they arise naturally.
Why would anyone want to know how similar two documents are? Students usually see that such a system could be used to recommend books: “If you liked this, you might also like….”* Students also suggest that it might be used to cluster documents into groups**. However, rarely does anyone suggest the application that I assign as a lab.
* This is called a “recommender system” in commercial applications.
** Indeed, a method of clustering called “hierarchical clustering” is based on distances between observations.
We can use similarity between documents to resolve authorship disputes. The most celebrated example concerns the Federalist Papers, first analyzed by statisticians Frederick Mosteller and David Wallace in the early 1960s (see here). Yes, even though the term “data science” has only become popular in the last 10 years, many of the ideas and methods are not new, dating back over 50 years. However, whereas Mosteller and Wallace did quite a bit of probability modeling, our approach is simpler and more direct.
The Federalist Papers are a collection of 85 essays penned by three Founding Fathers (Alexander Hamilton, John Jay, and James Madison) to drum up support for the new U.S. Constitution.* However, the essays were published under a pseudonym “Publius.” The authors of 70 of the essays have since been conclusively identified, but there are still 15 papers whose authorship is disputed.
* When I first started using this example in my class, few students were familiar with the Federalist Papers. However, the situation has greatly improved with the immense popularity of the musical Hamilton.
I give my students the texts of all 85 Federalist papers (here), along with the authors of the 70 undisputed essays:
Their task is to determine, for each of the 15 disputed essays, the most similar undisputed essays. The known authorships of these essays are then used to “vote” on the authorship of the disputed essay.
After writing some boilerplate code to read in and clean up the texts of the 85 papers, we split each document into a list of words and count up the number of times each word appears in each document. My students would implement this in the programming language Python, which is a general-purpose language that is particularly convenient for text processing, but the task could be carried out in any language, including R.
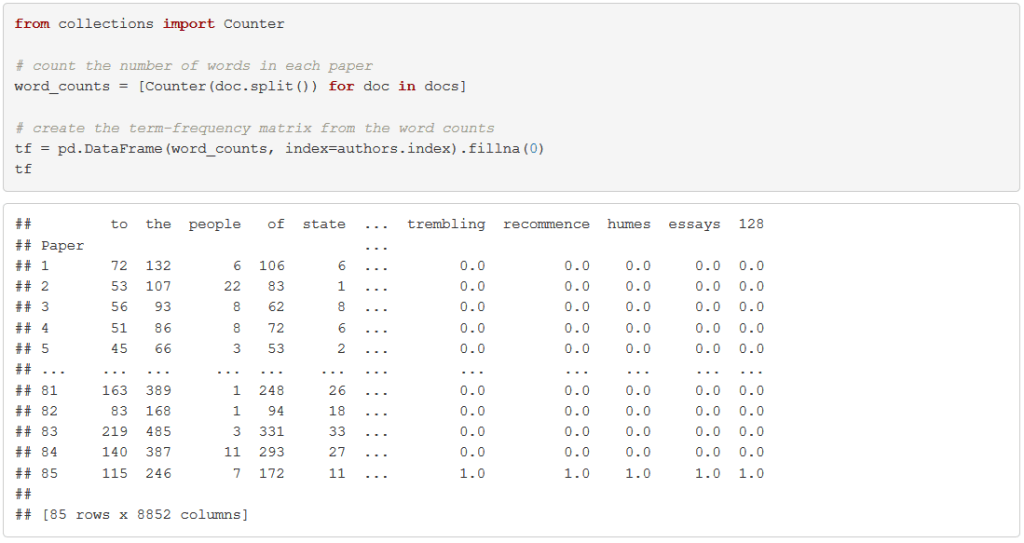
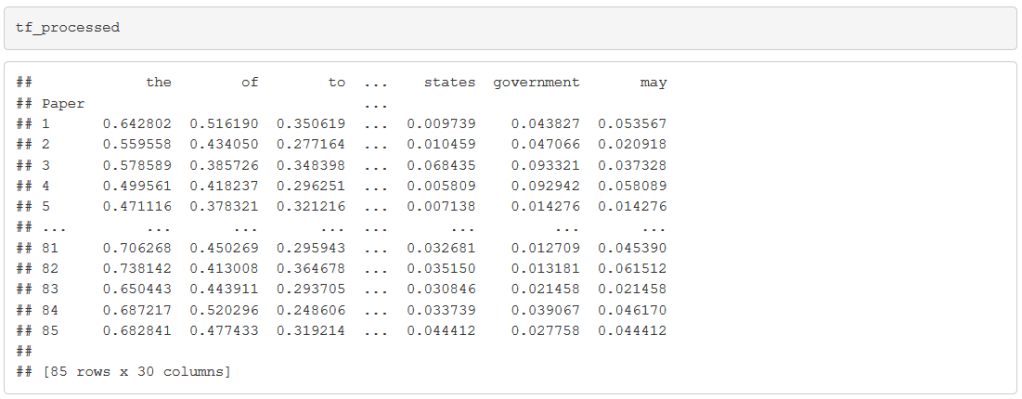
Rare context-specific words, like “trembling,” are less likely to be a marker of a writer’s style than general words like “which” or “as.” We restrict to the 30 most common words. We also normalize the vectors to be the same length so that distances are invariant to the length of the document. We end up with a table like the following:
Now, let’s look at one of the disputed papers: Federalist Paper #18. We calculate the Euclidean distance between this document and every other document:
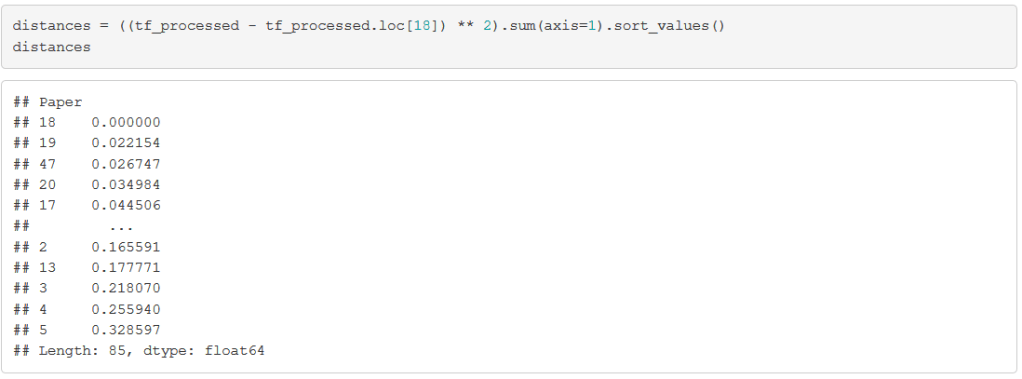
Of course, the paper that is most similar to Paper #18 is … itself. But the next few papers should give us some useful information. Let’s grab the authors of these most similar papers:
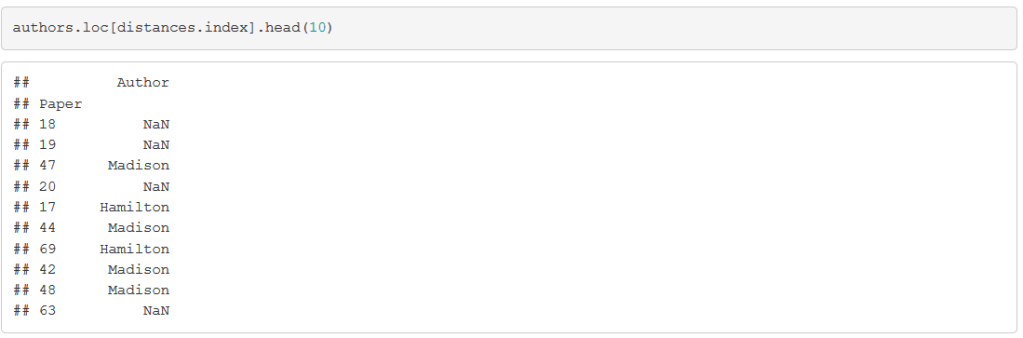
Although the second closest paper, Paper #19, is also disputed (which is why its author is given as the missing value NaN), the third closest paper was definitively written by Madison. If we look at the 3 closest papers with known authorship, 2 were written by Madison. This suggests attributing Paper #18 to Madison.
What the students just did is machine learning—training a K=3-nearest neighbors classifier on the 70 undisputed essays to predict the authorship Paper #18 — although we do not use any of that terminology. I find that students rarely have trouble understanding conceptually what needs to be done in this concrete problem, even if they struggle to grasp more abstract machine learning ideas such as training and test sets. Thus, I have started using this lab as a teaser for machine learning, which we study later in the course.
Next I ask students: How could you validate whether these predictions are any good? Of course, we have no way of knowing who actually wrote the disputed Federalist Papers, so any validation method has to be based on the 70 papers whose authorship is known.
After a few iterations, students come up with some variant of the following: for each of these 70 papers, we can find the 3 closest papers among the other 69 papers. Then, we can validate the prediction using these 3 closest papers against the known author of the paper, producing a table like the following:

In machine learning, this table is known as a “confusion matrix.” From the confusion matrix, we try to answer questions like:
- How accurate is this method overall?
- How accurate is this method for predicting documents written by Madison?
Most students assess the method overall by calculating the percentage of correct (or incorrect) predictions, obtaining an accuracy of 67/70 ≈ 96%.
However, I usually get two different answers to the second question:
- The method predicted 15 documents to be written by Madison, but only 13 were. So the “accuracy for predicting Madison” is 13/15 ≈ 87%.
- Madison actually wrote 14 of the documents, of which 13 were identified correctly. So the “accuracy for predicting Madison” is 13/14 ≈ 93%.
Which answer is right? Of course, both are perfectly valid answers to the question. These two different interpretations of the question are called “precision” and “recall” in machine learning, and both are important considerations.
One common mistake that students make is that they will include paper i itself as one of the three closest papers to paper i. They realize immediately why this is wrong when this is pointed out. If we think of our validation process as an exam, it is like giving away the answer key on an exam! This provides an opportunity to discuss ideas such as overfitting and cross-validation, again at an intuitive level, without using jargon.*
* The approach of finding the closest papers among the other 69 papers is formally known as “leave-one-out cross validation.”
I have several more labs in my data science class involving textual data. For example, I have students verify Zipf’s Law (learn about this from the video here) for different documents. A student favorite, which I adapted from my colleague Brian Granger (follow him on twitter here) is the “Song Lyrics Generator” lab, where students scrape song lyrics from their favorite artist from the web, train a Markov chain on the lyrics, and use the Markov chain to generate new songs by that artist. One of my students even wrote a Medium post (here) about this lab.
Although I am not an expert in natural language processing, I use textual data often in my data science class, because it is both rich and concrete. It has just enough complexity to stretch students’ imaginations about what data is and can do, but not so much that it is overwhelming to students with limited programming experience. The Federalist Papers lab in particular intersects with many technical aspects of data science, including linear algebra and machine learning, but the concreteness of the task allows us to discuss key ideas (such as vector norms and cross-validation) at an intuitive level, without using jargon. It also touches upon non-technical aspects of data science, including the emphasis on prediction (note the conspicuous absence of probability in this blog post) and the need for computing (the texts are long enough that the term frequencies are not feasible to count by hand). For students who know a bit of programming, this provides them with an end-to-end example of how to use data to solve real problems.
This guest post has been contributed by Dennis Sun. You can contact him at dsun09@calpoly.edu.

