#26 Group quizzes, part 2
In last week’s post (here), I mentioned that I give lots of group quizzes and consider them to be an effective assessment tool that promotes students’ learning. I provided six examples of quizzes, with five questions per quiz, that I have used with my students.
Now I pick up where I left off, offering seven more quizzes with comments on each. The topics of these quizzes include numerical variables and comparisons between groups.
As always, questions that I put to students appear in italics. A file containing all thirteen quizzes from the two posts, along with solutions, can be downloaded from a link at the end of this post.
7. Answer these questions:
- a) Suppose that a class of 10 students has the following exam scores: 60, 70, 50, 60, 90, 90, 80, 80, 40, 50. Determine the median of these 10 exam scores.
- b) Suppose that the average amount of sleep obtained by Cal Poly undergraduates last night was 6.8 hours, and the average amount of sleep obtained by Cal Poly graduate students last night was 7.6 hours. Is it reasonable to conclude that the average amount of sleep obtained last night among all Cal Poly students was (6.8 + 7.6)/2 = 7.2 hours? Explain.
- c) What effect does doubling every value in a dataset have on the mean? Explain your answer.
- d) What effect does adding 5 to every value in a dataset have on the standard deviation? Explain your answer.
- e) Create an example of 10 hypothetical exam scores (on a 0 – 100 scale) with the property that the mean is at least 20 points larger than the median. Also report the values of the mean and median for your example.
This quiz is a hodgepodge that addresses basic concepts of measures of center and variability, following up on topics raised in posts #5 (A below-average joke, here) and #6 (Two dreaded words, here). Some students think of part (a) as a “trick” question, but I think it’s important for students to remember to put data in order before declaring that the middle value (in this case, the average of the two middle values) is the median. For part (b), students should respond that this conclusion would only be valid if Cal Poly has the same number of undergraduate and graduate students. You could ask parts (c) and (d) as multiple choice questions by deleting the “explain” aspect. When I discuss part (e) with students afterward, I advise them to make such an example as extreme as possible. To make the mean much larger than the median, they could force the median to be zero by having six scores of zero. Then they can make the mean as large as possible by having four scores of 100. This makes the mean equal 400/10 = 40, with a median of 0.
8. Suppose that the mean age of all pennies currently in circulation in the U.S. is 12.3 years, and the standard deviation of these ages is 9.6 years. Suppose also that you take a random sample of 50 pennies and calculate the mean age of the pennies in your sample.
- a) Are the numbers 12.3 and 9.6 parameters or statistics? Explain briefly.
- b) Describe the sampling distribution of the sample mean penny age. Also produce a well-labeled sketch of this sampling distribution.
- c) Determine the probability that the sample mean age of your random sample of 50 pennies would be less than 10 years. (Show your work.)
- d) Are your answers to parts (b) and (c) approximately valid even if the distribution of penny ages is not normally distributed? Explain.
- e) Based on the values of the mean and standard deviation of penny ages, there is reason to believe that the distribution of penny ages is not normally distributed. Explain why.
This quiz is a challenging one, because the Central Limit Theorem is a challenging topic. Part (a) allows students to earn a fairly easy point. Those numbers are described as pertaining to all pennies in circulation, so they are parameters. I’m looking for four things in response to part (b): shape (normal), center (mean 12.3 years), and variability (SD 9.6/sqrt(50) ≈ 1.36 years), along with a sketch that specifies sample mean age as the axis label. Even if a student group has not answered parts (b) and (c) correctly, they can still realize that the large sample size of 50 means that the distribution of the sample mean will be approximately normal, so the answer to part (d) is that the answers to parts (b) and (c) would be valid. Part (e) is a very challenging one that brings to mind the AP Statistics question discussed in post #8 (End of alphabet, here). I have in mind there that the value 0 is only 1.28 standard deviations below the mean, so about 10% of pennies would have a negative age if the penny ages followed a normal distribution, which is therefore not plausible.
9. A study conducted in Dunedin, New Zealand investigated whether wearing socks over shoes could help people to walk confidently down an icy footpath*. Volunteers were randomly assigned either to wear socks over their usual footwear or to simply wear their usual footwear, as they walked down an icy footpath. An observer recorded whether or not the participant appeared to be walking confidently.
- a) Is this an observational study or an experiment? Explain briefly.
- b) Identify the explanatory and response variables.
- c) Does this study make use of random sampling, random assignment, both, or neither?
- d) Did the researchers use randomness in order to give all walkers in New Zealand the same chance of being selected for the study? Answer YES or NO.
- e) Did the researchers use randomness in order to produce groups that were as similar as possible in all respects before the explanatory variable was imposed? Answer YES or NO.
* This may not be scientific research of the greatest import, but this is a real study, not a figment of my imagination. That this study was conducted in New Zealand makes it all the more appealing. I hope my students enjoy this context as much as I do, but they are probably too focused on answering the quiz questions to notice.
Parts (a) – (c) should come as no surprise to students, as I ask these questions all the time in class. (See post #11, Repeat after me, here.) I especially like parts (d) and (e), which ask about the purpose of randomness in data collection. Most students realize that random assignment does not give all walkers the same chance of being selected but does try to produce groups that are as similar as possible. (See posts #19 and #20, Lincoln and Mandela, here and here, for more about random sampling and random assignment.)
10. Recall that a study conducted in Dunedin, New Zealand investigated whether wearing socks over shoes could help people to walk confidently down an icy footpath*. Participants were randomly assigned to wear socks over their usual footwear, or to simply wear their usual footwear, as they walked down an icy footpath. One of the response variables measured was whether an observer considered the participant to be walked confidently. Results are summarized in the 2×2 table of counts below:

For parts (a) – (c), suppose that you conduct a by-hand simulation analysis to investigate whether wearing socks over shoes increases people’s confidence while walking down an icy footpath. For parts (d) and (e), consider the results of such a simulation analysis performed with technology.
- a) What would be the assumption involved with producing the simulation analysis? Choose one of the following options: A. That wearing socks over shoes has no effect on walkers’ confidence; B. That wearing socks over shoes has some effect on walkers’ confidence; C. That walkers are equally likely to feel confident or not, regardless of whether they wear socks over shoes or not; D. That walkers are more likely to feel confident if they wear socks over shoes
- b) How many cards would you use in the simulation analysis? What would the color breakdown be?
- c) How many cards would you deal out into groups? How many times would you repeat this process?
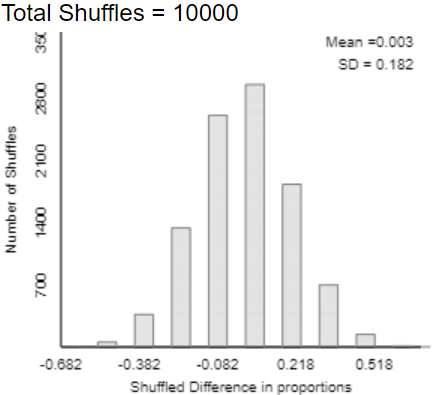
- d) The graph below displays the results of a simulation analysis with 10,000 repetitions, displaying the distribution of the difference in success proportions between the two groups. Describe how you would calculate an approximate p-value from this graph (i.e., where would you count?).
- e) Based on the 2×2 table of data and on this graph of simulation results, how much evidence do the data provide in support of the conjecture that wearing socks over shoes increases people’s confidence while walking down an icy footpath? Choose one of the following options: A. little or no evidence; B. moderate evidence; C. strong evidence; D. very strong evidence.
* This study is too fascinating to use only once!
This quiz assesses how well students understood a class activity about simulation-based inference for comparing proportions between two groups*. Part (a) asks for the null hypothesis, without using that term. Parts (b) – (c) concern the nuts and bolts of conducting a simulation analysis by hand. Parts (d) and (e) address using the simulation analysis to draw a conclusion. The hardest part for students is realizing that they need to see where the observed value of the statistic (difference in success proportions between the two groups) falls in the simulated null distribution. I could have made this more apparent by first asking students to calculate the value of the statistic. Instead I only give a small hint at the beginning of part (e) by reminding students to use the 2×2 table of observed counts as well as the graph of simulation results. In this case the observed value of the statistic (10/14 – 8/15 ≈ 0.181) is not a surprising result in the simulated null distribution, so the study provides little or no evidence that wearing socks over shoes is helpful.
* My next blog post (#27) will describe and discuss such a class activity.
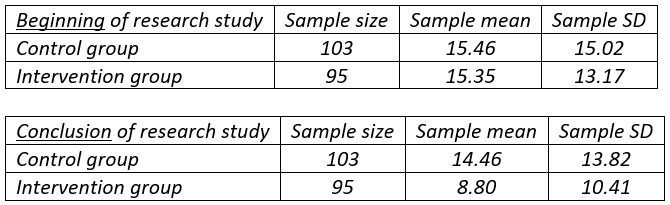
11. Researchers at Stanford University studied whether a curriculum could help to reduce children’s television viewing. Third and fourth grade students at two public elementary schools in San Jose were the subjects. One of the schools, chosen at random, incorporated an 18-lesson, 6-month classroom curriculum designed to reduce watching television and playing video games, whereas the other school made no changes to its curriculum. At the beginning and end of the study, all children were asked to report how many hours per week they spent on these activities, both before the curriculum intervention and afterward. The tables below summarize reported amounts of television watching, first at the beginning of the study and then at its conclusion:
- a) Is the response variable in this study categorical or numerical?
- b) The difference between the groups can be shown not to be statistically significant at the beginning of the study. Do you think the researchers would be pleased by this result? Explain why or why not.
- c) Even if the distributions of reported amounts of television watching per week are sharply skewed, would it still be valid to apply a two-sample t-test on these data? Explain briefly.
- d) Calculate the value of the test statistic for investigating whether the two groups differ with regard to average amount of television watching per week.
- e) Based on the value of the test statistic, summarize your conclusion for the researchers.
Part (a) is quite straightforward, offering an easy point for students. I really like part (b), which asks students to realize that a non-significant difference between the groups at the beginning of the study is a good thing. The lack of significance suggests that random assignment achieved its goal of producing similar groups prior to the intervention. For part (c) students should recognize that the large sample sizes establish that the two-sample t-test is valid even with skewed distributions. Notice that the only calculation in the quiz is part (d). The value of the test statistic in part (d) turns out to be 3.27, which is large enough to conclude in part (e) that the intervention reduced the mean amount of television watching.
12. Answer the following:
- a) Would you expect to find a positive or negative correlation coefficient between high temperature on January 1, 2020 and distance from the equator, for a sample consisting of one city from each of the 50 U.S. states? Explain briefly.
- b) Suppose that you record the daily high temperature and the daily amount of ice cream sold by an ice cream vendor at your favorite beach next summer, starting on the Friday of Memorial Day weekend and ending on the Monday of Labor Day weekend. Would you expect to find a positive or negative correlation coefficient between these variables? Explain briefly.
- c) Suppose that every student in this class scored 5 points lower on the second exam than on the first exam. Consider the correlation coefficient between first exam score and second exam score. What would the value of this correlation coefficient be? Explain briefly
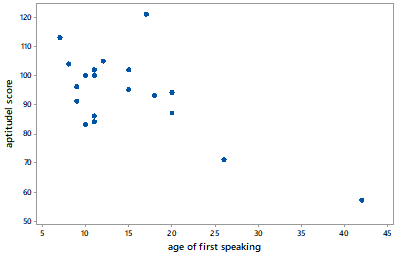
Parts (d) and (e) pertain to the graph below, which displays data on the age (in months) at which a child first speaks and the child’s score on an aptitude test taken later in childhood:
- d) Is the value of the correlation coefficient between these variables positive or negative?
- e) Suppose that the child who took 42 months to speak were removed from the analysis. Would the value of the correlation coefficient between the variables be closest to -1, 0, or 1?
This quiz addresses association and correlation between two numerical variables. Parts (a) and (b) ask students to think about a context to determine whether an association would be positive or negative. Part (c) is very challenging, as I discussed in post #21 (Twenty final exam questions, here). Many students believe that the correlation must be negative, and some even respond that the correlation coefficient will equal -5! The correct answer is that the correlation would be exactly 1.0, because the data would fall on a straight line with positive slope.
Parts (d) and (e) pertain to one of my all-time favorite datasets, which I encountered in Moore and McCabe’s Introduction to the Practice of Statistics near the beginning of my teaching career. For this quiz I want students to realize that the correlation coefficient is negative but would be close to zero if the child who took the longest to speak were removed.
13. Some of the statistical inference procedures that we have studied include:
- A. One-sample z-procedures for a proportion
- B. Two-sample z-procedures for comparing proportions
- C. One-sample t-procedures for a mean
- D. Two-sample t-procedures for comparing means
- E. Paired-sample t-procedures for comparing means
For each of the following questions, identify (by capital letter) which procedure you would use to address that question. (Be aware that some letters may be used more than once, others not at all.)
- a) Do cows tend to produce more milk if their handler speaks to them by name every day than if the handler does not speak to them by name? A farmer randomly assigned half of her cows to each group and then compared how much milk they produced after one month.
- b) A baseball coach wants to investigate whether players run more quickly from second base to home plate if they take a wide angle or a narrow angle around third base. He recruits 20 players to serve as subjects for a study. Each of the 20 players runs with each method (wide angle, narrow angle) once.
- c) Does the average length of a sentence in a novel written by John Grisham exceed the average length of a sentence in a novel written by Louise Penny? Students took a random sample of 100 sentences from each author’s most recent novel and recorded the number of words in each sentence.
- d) Have more than 25% of Cal Poly students have been outside of California in the year 2019?
- e) Are Stanford students more likely to have been outside of California in the year 2019 than Cal Poly students?
I give a quiz like this once or twice in every course. Students need practice with identifying which procedure to use in a particular situation. It’s easy and appropriate for students to focus on one topic at a time, so I think we teachers need to ask questions like this that require students to synthesize what they’ve learned across topics.
Notice that the words proportion and mean do not appear in any of the five parts of this quiz, so students cannot simply look for those key words. I tell students that the key to answering questions like this is to start by identifying the variable(s) and their types (categorical or numerical) and roles (explanatory or response).
The last of the six GAISE recommendations (here) is: Use assessments to improve and evaluate student learning. The improve part of that recommendation can be very challenging to implement successfully. I have found group quizzes to be very effective for motivating students to help each other with developing and strengthening their understanding of statistical concepts.
P.S. The study about wearing socks over shoes can be found here. The study about children’s television viewing can be found here. The data on age of first speaking can be found here.
P.P.S. The following link contains a Word file with the thirteen quizzes from this post and the previous one, along with solutions. Teachers should feel free to modify this file for use with their own students.


Trackbacks & Pingbacks