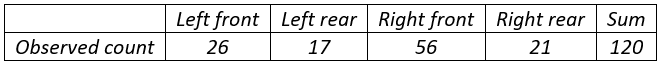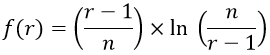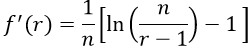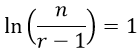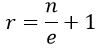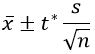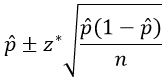#55 Classroom assessment with clicker questions
This guest post has been contributed by Roxy Peck. You can contact her at rpeck@calpoly.edu.
I consider Roxy Peck to be one of the most influential statistics educators of the past 30 years. Her contributions extend beyond her widely used and highly regarded textbooks, encompassing the teaching and learning of statistics at secondary and undergraduate levels throughout California, the United States, and beyond. Roxy has been an inspiration and role model throughout my career (and for many others, I’m sure). I greatly appreciate Roxy’s taking the time to write this guest post about the use of clicker questions for classroom assessment.
Asking good questions is key to effective and informative assessment. Faculty use tests and quizzes to help them assess student learning, often for the purposes of assigning course grades. In post #25 of this blog (Group quizzes, part 1, here), Allan says he uses lots of quizzes in his classes because they also provide students with the opportunity to improve their understanding of the material and to assess how well they understand the material, and no one would argue with the importance of those assessment goals. But in this blog post, I want to talk about another form of assessment – classroom assessment. Classroom assessment is the systematic collection and analysis of information for the purpose of improving instruction. The more you know about what your students know and understand, the better you can plan and adjust your classroom practice.
I think that the best types of classroom assessments are timely and inform teaching practice, sometimes in real time. For me, the worst-case scenario is to find out when I am grading projects or final exams that students didn’t get something important. That’s too late for me to intervene or to do anything about it but hang my head and pout. That’s why I think good classroom assessment is something worth thinking carefully about.
My favorite tool for classroom assessment is the use of “clicker questions.” These are quick, usually multiple choice, questions that students can respond to in real time. The responses are then summarized and displayed immediately to provide quick feedback to both students and the instructor. There are many ways to implement the use of clicker questions, ranging from low tech to high tech. I will talk a little about the options toward the end of this post, but first I want to get to the main point, and that’s what I think makes for a good clicker question.
Clicker questions can be used to do real-time quizzes, and also as a way create and maintain student engagement and to keep students involved during class even in situations where class sizes are large. But if the goal is to also use them to inform instruction, they need to be written to reveal more than just whether a student knows or understands a particular topic. They need to be written in a way that will help in the decision of what to do next, especially if more than a few students answer incorrectly. That means that if I am writing a clicker question, I need to write “wrong” answers that capture common student errors and misconceptions.
Clicker questions can be quick and simple. For example, consider the following question:
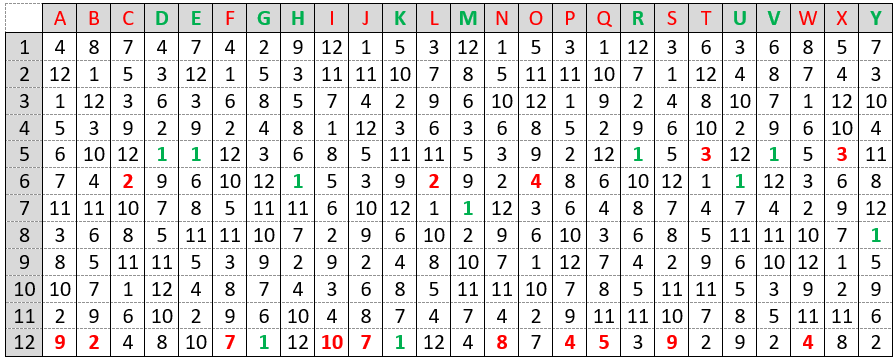
Seventy-five (75) college students were asked how many units of coursework they were enrolled in during the current semester. The resulting data are summarized in the following frequency table:

What is the median for this dataset? Options: A) 10; B) 11; C) 12
For this question, the correct answer is 12. What are students who answer 10 or 11 thinking? A common student error is for students to confuse the frequencies with the actual data. A student who makes this error would find the median of the frequencies, which is 10. Another common student error is to confuse the possible values for number of units given in the frequency table with the actual data. A student who makes this error would find the median of the possible values (the numbers in the “Number of Units” column) and answer 11. The main thing to think about when putting a question like this together are these common student errors. That’s not a new idea when writing good multiple choice questions for student assessment, but the goal in writing for classroom assessment is to also think about what I am going to do if more than a few students pick one of the incorrect options. With this question, if almost all students get this correct, I can move on. But if more than a few students select incorrect answer (A), I can immediately adapt instruction to go back and address the particular student misunderstanding that leads to that incorrect answer. And I can do that in real time, not two weeks later after I have graded the first midterm exam.
Another example of a good clicker question that is related to the same student misunderstanding where frequencies are mistaken for data values is the following:
Which of the three histograms summarizes the dataset with the smallest standard deviation?
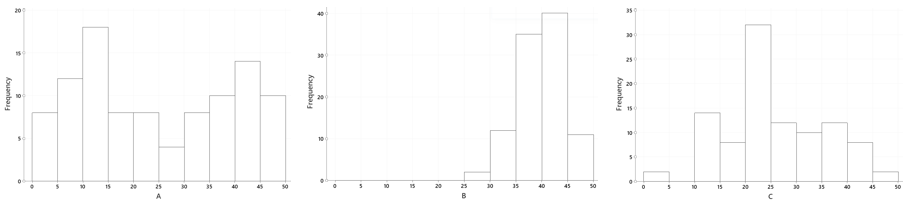
Students choosing either answers (A) or (C) are focusing on variability in the frequencies rather than variability in the data values. If I see students going for those answers, I can address that immediately, either through classroom discussion or by having students talk in small groups about the possibilities and come to an understanding of why answer choice (B) is the correct one.
Here is another example of a simple question that gets at understanding what is being measured by the interquartile range:
Which of the two dotplots displays the dataset with the smaller IQR?

What is the error in thinking for the students who choose answer (B)? What would you do next if you asked this question in class and more than a few students selected this incorrect option?
I will only use a clicker question if I have a plan for what I will do as an immediate reaction to how students respond. Often, I can see that it is safe to move on, knowing that students are with me and that further discussion is not needed. In other cases, I find that I have some work to do!
So what is the difference between a clicker question and a multiple choice question? I think that pretty much any well-written multiple choice question can be used as a clicker question, so strategies for writing good multiple choice questions apply here as well. But I think of a good clicker question as a good multiple choice question that I can deliver in real time AND that is paired with a plan for how student responses will inform and change what I do next in class. I have used multiple choice questions from sources like the LOCUS and ARTIST projects (described at the end of this post) as clicker questions.
Consider the following question from the ARTIST question bank:
A newspaper article claims that the average age for people who receive food stamps is 40 years. You believe that the average age is less than that. You take a random sample of 100 people who receive food stamps, and find their average age to be 39.2 years. You find that this is significantly lower than the age of 40 stated in the article (p < 0.05). What would be an appropriate interpretation of this result?
- (A) The statistically significant result indicates that the majority of people who receive food stamps is younger than 40.
- (B) Although the result is statistically significant, the difference in age is not of practical importance.
- (C) An error must have been made. This difference is too small to be statistically significant.
This is a multiple choice question that makes a great clicker question because students who choose answer (A) or answer (C) have misconceptions (different ones) that can be addressed in subsequent instruction.
The same is true for the following clicker question:
In order to investigate a claim that the average time required for the county fire department to respond to a reported fire is greater than 5 minutes, county staff determined the response times for 40 randomly selected fire reports. The data was used to test H0: μ = 5 versus Ha: μ > 5 and the computed p-value was 0.12. If a 0.05 level of significance is used, what conclusions can be drawn?
- (A) There is convincing evidence that the mean response time is 5 minutes (or less).
- (B) There is convincing evidence that the mean response time is greater than 5 minutes.
- (C) There is not convincing evidence that the mean response time is greater than 5 minutes.
If very many students choose response (A), I need to revisit the meaning of “fail to reject the null hypothesis.” If many students go for (B), I need to revisit how to reach a conclusion based on a given p-value and significance level. And if everyone chooses (C), I am happy and can move on. Notice that there is a reason that I put the incorrect answer choice (A) before the correct answer choice (C). I did that because I need to know that students recognize answer choice (A) as wrong and want to make sure that they understand that answer is incorrect. If the correct choice (C) came first, they might just select that because it sounds good without understanding the difference between what is being said in (A) – convincing evidence for the null hypothesis – and what is being said in answer choice (C) – not convincing evidence against the null hypothesis.
I have given some thought about whether to have clicker question responses count toward the student’s grade and have experimented a bit with different strategies. Some teachers give participation points for answering a clicker question, whether the answer is correct or not. But because the value of clicker questions to me is classroom assessment, I really want students to try to answer the question correctly and not just click a random response. I need to know that students are making a sincere effort to answer correctly if I am going to adapt instruction based on the responses. But I also don’t want to put a heavy penalty for an incorrect answer. If students are making an effort to answer correctly, then I share partial responsibility for incorrect answers and may need to declare a classroom “do-over” if many students answer incorrectly. I usually include 3 to 4 clicker questions in a class period, so what I settled on is that students could earn up to 2 points for correct responses to clicker questions in each class period where I use clicker questions. While I use them in most class meetings, some class meetings are primarily activity-based and may not incorporate clicker questions (although clicker questions can sometimes be a useful in the closure part of a classroom activity as a way to make sure that students gained the understanding that the activity was designed to develop). Of course, giving students credit for correct answers assumes that you are not using the low-tech version of clicker questions described below, because that doesn’t keep track of individual student responses to particular questions.
Teachers can implement clicker questions in many ways. For example, ABCD cards can be used for clicker questions if you are teaching in a low tech or no tech environment:

With ABCD cards, each student has a set of cards (colored cards make it easier to get a quick read on the responses). The instructor poses a question, provides time to think, and then has each student hold up the card corresponding to the answer. By doing a quick look around the classroom, the instructor gets a general idea of how the students responded.
The downside of ABCD cards is that there is no way to collect and display the responses or to record the responses for the purpose of awarding credit for correct responses. Students can also see which students chose which answers, so the responses are not anonymous to other students. In a big lecture class, it is also difficult for the instructor to “read” the class responses.
Physical clickers are small devices that students purchase. Student responses are picked up by a receiver and once polling is closed responses can be summarized and displayed immediately to provide quick feed back to both students and instructor. Several companies market clickers with educational discounts, such as TurningPoint (here) and iClickers (here).
There are also several web apps for polling that can be used for clicker questions if your students have smart phones or web access. A free app that is popular with teachers is Kahoot! (free for multiple choice; more question types, tools and reports for $3 or $6 per month, here). Another possibility is Poll Everywhere (free up to 25 students, then $120 per year for up to 700 students, here).
And finally, Zoom and some classroom management systems have built-in polling. I have used Zoom polls now that I am delivering some instruction online, and Zoom polls allow you to summarize and share results of polling questions. Zoom also has a setting that tracks individual responses if you want to use it for the purposes of assigning credit for correct answers.
I think incorporating good clicker questions has several benefits. It provides immediate feedback to students (they can see the correct answer and how other students answered), and it has changed the way that I interact with students and how students interact with the course. Students are more engaged and enjoy using this technology in class. They pay more attention because they never know when a clicker question is coming, and they want to get it right. And if they get it wrong, they want to see how other students answered.
But one important final note: If you are going to use clicker questions, it is really important to respond to them and be willing to modify instruction based on the responses. If students see that many did not get the right answer and you just say “Oh wow. Lots of you got that wrong, the right answer is C” and then move on as if you had never asked the question, students will be frustrated. On the other hand, if you respond and adjust instruction, students see that you are making student understanding a top priority!
P.S. LOCUS (Levels of Conceptual Understanding in Statistics, here) is a collection of multiple-choice and free-response assessment items that assess conceptual understanding of statistics. Items have all been tested with a large group of students, and the items on the website include commentary on student performance and common student errors. Designed to align with the Common Core State Standards, they follow the K-12 statistics curriculum. Because there is a great deal of overlap in the high school standards with the current college intro statistics course, there are many items (those for level B/C) that are usable at the college level.
ARTIST (Assessment Resource Tools for Improving Statistical Thinking, here) is a large bank of multiple-choice and free-response assessment items, which also includes several scales that measure understanding at the course level and also at a topic level. At the course level, the CAOS test (Comprehensive Assessment of Outcomes for a First Course in Statistics) consists of 40 conceptual multiple-choice questions. The topic scales are shorter collections of multiple-choice questions on a particular topic. There are more than 1000 items in the item bank, and you can search by topic and by question type, select items to use in a test and download them as a word document that you can edit to suit your own needs. You must register to use the item bank, but there is no cost.
This guest post has been contributed by Roxy Peck. You can contact her at rpeck@calpoly.edu.